[论文解读] Cobra: Extending Mamba to Multi-Modal Large Language Model for Efficient Inference
Cobra 构建一个通过将线性时间 Mamba 状态空间模型与视觉编码器整合的多模态大语言模型,在保持竞争性准确性的同时,推理速度比 Transformer 基线快 3–4 倍,参数量约为较大模型的 43%。
In recent years, the application of multimodal large language models (MLLM) in various fields has achieved remarkable success. However, as the foundation model for many downstream tasks, current MLLMs are composed of the well-known Transformer network, which has a less efficient quadratic computation complexity. To improve the efficiency of such basic models, we propose Cobra, a linear computational complexity MLLM. Specifically, Cobra integrates the efficient Mamba language model into the visual modality. Moreover, we explore and study various modal fusion schemes to create an effective multi-modal Mamba. Extensive experiments demonstrate that (1) Cobra achieves extremely competitive performance with current computationally efficient state-of-the-art methods, e.g., LLaVA-Phi, TinyLLaVA, and MobileVLM v2, and has faster speed due to Cobra's linear sequential modeling. (2) Interestingly, the results of closed-set challenging prediction benchmarks show that Cobra performs well in overcoming visual illusions and spatial relationship judgments. (3) Notably, Cobra even achieves comparable performance to LLaVA with about 43% of the number of parameters. We will make all codes of Cobra open-source and hope that the proposed method can facilitate future research on complexity problems in MLLM. Our project page is available at: https://sites.google.com/view/cobravlm.
研究动机与目标
- 阐明基于 Transformer 的多模态大语言模型在二次复杂度方面的效率限制。
- 提出使用线性时间状态空间模型(Mamba)进行多模态处理的 Cobra 架构。
- 研究模态融合方案,以有效整合视觉与语言信息。
- 展示 Cobra 在标准 VLM 基准上的竞争性能和更高的速度。
- 展示在保持性能的同时潜在的参数量减少。
提出的方法
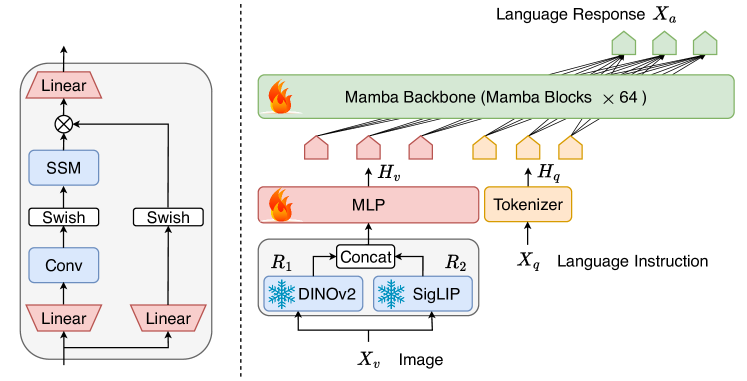
- 使用视觉编码器栈(DINOv2 + SigLIP)从图像中提取视觉表示。
- 引入投影模块将视觉标记对齐到 Mamba 标记空间(MLP 或替代方法)。
- 采用 Mamba 作为骨干,包含 64 个块,以自回归方式处理连接的视觉与文本嵌入。
- 在 Mamba 内融合视觉与语言模态,探索不同的融合方案以优化多模态表示。
- 通过对整个 LLM 主干和投影器在大约 1.2M 图文样本上进行两轮训练,对多个数据集进行端到端微调。
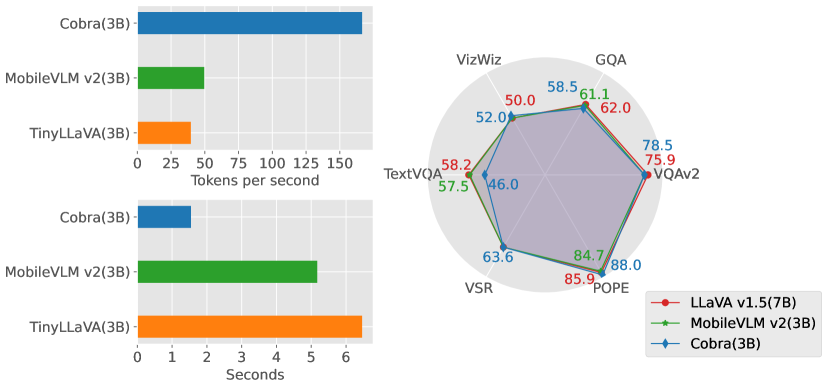
实验结果
研究问题
- RQ1当与视觉编码器搭配时,线性时间状态空间模型(Mamba)是否能有效支持多模态大语言建模?
- RQ2哪些视觉编码器和投影策略能够最好地保留视觉信息,以实现 Cobra 的准确多模态推理?
- RQ3相对于参数预算相近的 Transformer 基线,Cobra 在开放式 VQA 与封闭集空间/幻觉基准中的表现如何?
- RQ4采用状态空间骨干的 MLLMs 相比 Transformer 基线,在推理速度与内存使用方面的提升有哪些?
主要发现
| 模型 | LLM | VQA_v2 | GQA | VizWiz | VQA_T | VSR | POPE |
|---|---|---|---|---|---|---|---|
| OpenFlamingo | MPT-7B | 52.7 | - | 27.5 | 33.6 | - | - |
| BLIP-2 | Vicuna-13B | - | 41.0 | 19.6 | 42.5 | 50.9 | - |
| MiniGPT-4 | Vicuna-7B | 32.2 | - | - | - | - | - |
| InstructBLIP | Vicuna-7B | - | 49.2 | 34.5 | 50.1 | 54.3 | - |
| InstructBLIP | Vicuna-13B | - | 49.5 | 33.4 | 50.7 | 52.1 | - |
| Shikra | Vicuna-13B | 77.4 | - | - | - | - | - |
| IDEFICS | LLaMA-7B | 50.9 | - | 35.5 | 25.9 | - | - |
| IDEFICS | LLaMA-75B | 60.0 | - | 36.0 | 30.9 | - | - |
| Qwen-VL | Qwen-7B | 78.2 | 59.3 | 35.2 | 63.8 | - | - |
| LLaVA v1.5 | Vicuna-7B | 78.5 | 62.0 | 50.0 | 58.2 | - | 85.9 |
| Prism | LLaMA-7B | 81.0 | 65.3 | 52.8 | 59.7 | 59.6 | 88.1 |
| ShareGPT4V | Vicuna-7B | 80.6 | 57.2 | - | - | - | - |
| MoE-LLaVA | StableLM-1.6B | 76.7 | 60.3 | 36.2 | 50.1 | - | 85.7 |
| MoE-LLaVA | Phi2-2.7B | 77.6 | 61.4 | 43.9 | 51.4 | - | 86.3 |
| Llava-Phi | Phi2-2.7B | 71.4 | - | 35.9 | 48.6 | - | 85.0 |
| MobileVLM v2 | MobileLLaMA-2.7B | - | 61.1 | - | 57.5 | - | 84.7 |
| TinyLLaVA | Phi2-2.7B | 79.9 | 62.0 | - | 59.1 | - | 86.4 |
| Cobra (ours) | Mamba-2.8B | 75.9 | 58.5 | 52.0 | 46.0 | 63.6 | 88.0 |
- Cobra 在具备线性序列建模的同时,与高效的最先进方法(如 LLaVA-Phi、TinyLLaVA、MobileVLM v2)相比,取得了竞争性的性能。
- Cobra 在涉及空间关系判断的封闭集合任务以及减少视觉幻觉方面表现出强健的鲁棒性。
- Cobra 具有大约 LLaVA v1.5 7B 的 43% 参数,在若干基准上达到可比性能,突出效率优势。
- Cobra 的推理速度显著更快(例如,在相似尺寸下比 MobileVLM v2 和 TinyLLaVA 快 3×–4×)。
- 消融研究表明将 DINOv2 与 SigLIP 结合可提升结果,对话微调的 Mamba 模型进一步微调可获得更好的指令跟随性能。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。