[论文解读] Cognitive Constraint Simulation and the Geometry of Human Authorship: A First-Principles Theory of AI Text Detection
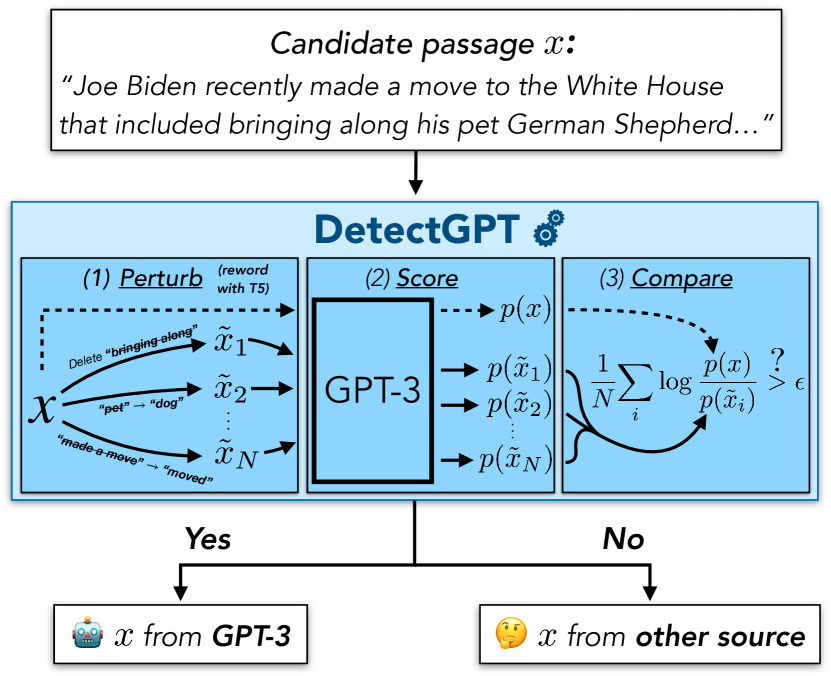
DetectGPT 引入了一种零样本文本检测方法,利用模型对数概率的局部曲率来区分模型生成的文本与人类撰写的文本,且无需在真实/生成样本上进行训练。
The increasing fluency and widespread usage of large language models (LLMs) highlight the desirability of corresponding tools aiding detection of LLM-generated text. In this paper, we identify a property of the structure of an LLM's probability function that is useful for such detection. Specifically, we demonstrate that text sampled from an LLM tends to occupy negative curvature regions of the model's log probability function. Leveraging this observation, we then define a new curvature-based criterion for judging if a passage is generated from a given LLM. This approach, which we call DetectGPT, does not require training a separate classifier, collecting a dataset of real or generated passages, or explicitly watermarking generated text. It uses only log probabilities computed by the model of interest and random perturbations of the passage from another generic pre-trained language model (e.g., T5). We find DetectGPT is more discriminative than existing zero-shot methods for model sample detection, notably improving detection of fake news articles generated by 20B parameter GPT-NeoX from 0.81 AUROC for the strongest zero-shot baseline to 0.95 AUROC for DetectGPT. See https://ericmitchell.ai/detectgpt for code, data, and other project information.
研究动机与目标
- 使用零-shot 检测来识别一段文本是否由特定语言模型生成。
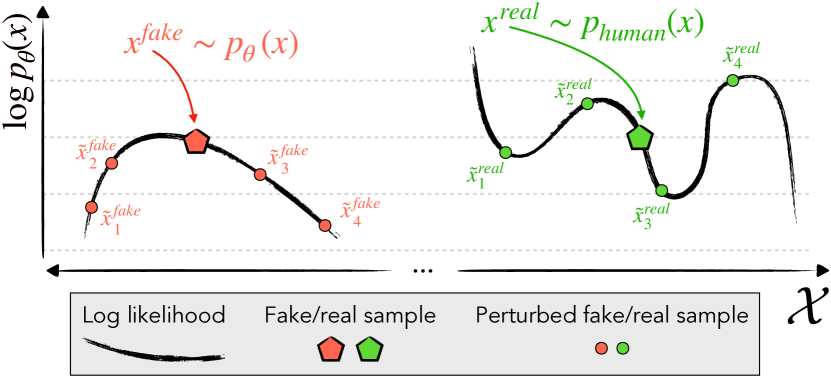
- 探究机器生成文本是否位于模型对数概率函数的负曲率区域。
- 开发一个实用的检测器,不需要带标签的真实/生成数据或文本水印。
- 在多个数据集和模型规模上验证该方法,并与现有的零-shot 基线进行比较。
提出的方法
- 假设模型生成的文本位于 log p(x) 的负曲率区域。
- 定义扰动差异 d(x,p,q) = log p(x) - E_{ ilde{x}~q(.|x)} log p( ilde{x}).
- 通过 Hutchinson 的迹估计器和有限差分来估计 log p(x) 的负 Hessian 跟踪迹,以近似曲率。
- 使用掩码填充扰动模型(例如 T5)在数据流形上生成附近文本。
- 计算归一化的扰动差异并设阈值以判断 x 是否由 p 生成。
- 提供算法 DetectGPT,使用源模型 p_theta 及来自 q 的扰动对 x 进行评分,并设定阈值 epsilon。
实验结果
研究问题
- RQ1由给定的大型语言模型生成的文本是否在模型对数概率的负曲率区域中比人类撰写的文本更显著?
- RQ2使用局部曲率信息的零-shot 检测器能否超越依赖全局对数概率的现有零-shot 方法?
- RQ3DetectGPT 对改写、不同扰动模型和跨模型评分场景的鲁棒性如何?
- RQ4模型/扰动容量、扰动数量和数据域对检测性能的影响是什么?
主要发现
- DetectGPT 在多个模型(1.5B 至 20B 参数)和领域中,对零-shot 基线的 AUROC 持续提升。
- 与负曲率相关的扰动差异,在实证测试中可靠地区分模型生成文本与人类撰写文本。
- 使用更大的掩码填充扰动模型(如 T5 变体)和更多扰动可将检测提升至收敛,大约 100 次扰动。
- 在机器生成文本的改写/修订以及不同解码策略下,检测仍然强健,零-shot 检测器通常比监督方法对领域更具泛化性。
- 跨模型评分显示,当由生成文本的相同模型进行评分时,DetectGPT 最为有效,但使用代理评分器时仍有用。
- DetectGPT 在若干设置中对最强零-shot 基线的 AUROC 提升约 0.1(如论文所述)。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。