[论文解读] Collaborating with language models for embodied reasoning
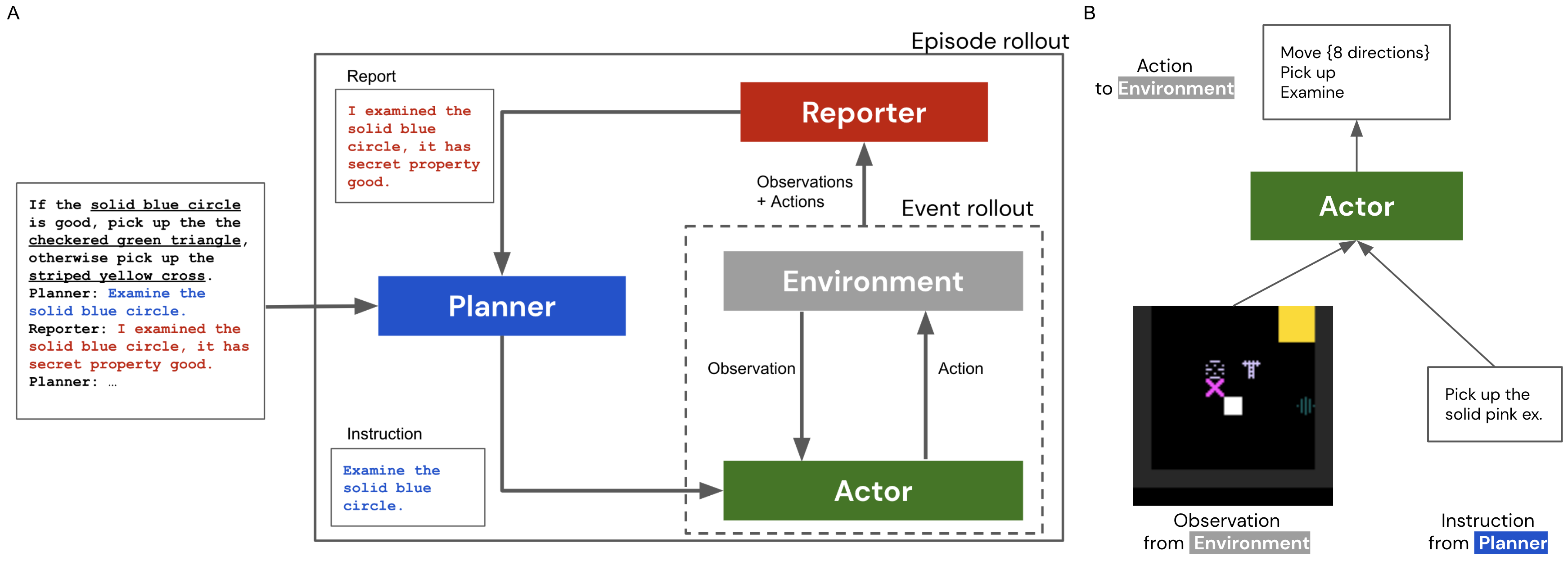
该论文提出了一种 Planner-Actor-Reporter 架构,将预训练语言模型与具身 RL 代理相结合,在二维网格世界中进行多步推理和信息收集,展示零-shot 泛化和使用 RL 训练的报告以提升协作效果。
Reasoning in a complex and ambiguous environment is a key goal for Reinforcement Learning (RL) agents. While some sophisticated RL agents can successfully solve difficult tasks, they require a large amount of training data and often struggle to generalize to new unseen environments and new tasks. On the other hand, Large Scale Language Models (LSLMs) have exhibited strong reasoning ability and the ability to to adapt to new tasks through in-context learning. However, LSLMs do not inherently have the ability to interrogate or intervene on the environment. In this work, we investigate how to combine these complementary abilities in a single system consisting of three parts: a Planner, an Actor, and a Reporter. The Planner is a pre-trained language model that can issue commands to a simple embodied agent (the Actor), while the Reporter communicates with the Planner to inform its next command. We present a set of tasks that require reasoning, test this system's ability to generalize zero-shot and investigate failure cases, and demonstrate how components of this system can be trained with reinforcement-learning to improve performance.
研究动机与目标
- 证明一个预训练语言模型可以作为规划者,向具身代理(Actor)发出自然语言指令。
- 展示 Reporter 如何将 Actor 的观测翻译回 Planner,以形成指令改进的闭环。
- 评估规划者在模型规模和任务变体上的零-shot 泛化能力和鲁棒性。
- 研究通过强化学习训练 Reporter 以提升协作、减少手工反馈。
- 分析在报告不完善时系统的失效模式与鲁棒性。
提出的方法
- 实现三部分系统:Planner(LSLM)、Actor(RL 代理)和 Reporter(将 Actor 数据翻译回 Planner)。
- 在 7B 与 70B 参数的 Chinchilla-based LLM 作为 Planner,使用 few-shot 提示。
- 在简单的抓取与检查任务上训练 Actor;观察者在环境中使用 Reporter 反馈指令。
- 定义一个二维部分可观测网格世界,按颜色、形状和纹理区分对象;允许检查和拾取动作。
- 实验需要信息收集和基于报告属性的条件决策的秘密属性任务。
- 评估 Planner 对不完美 Report 的鲁棒性,并探索用 RL 训练 Reporter 以优化 reward。
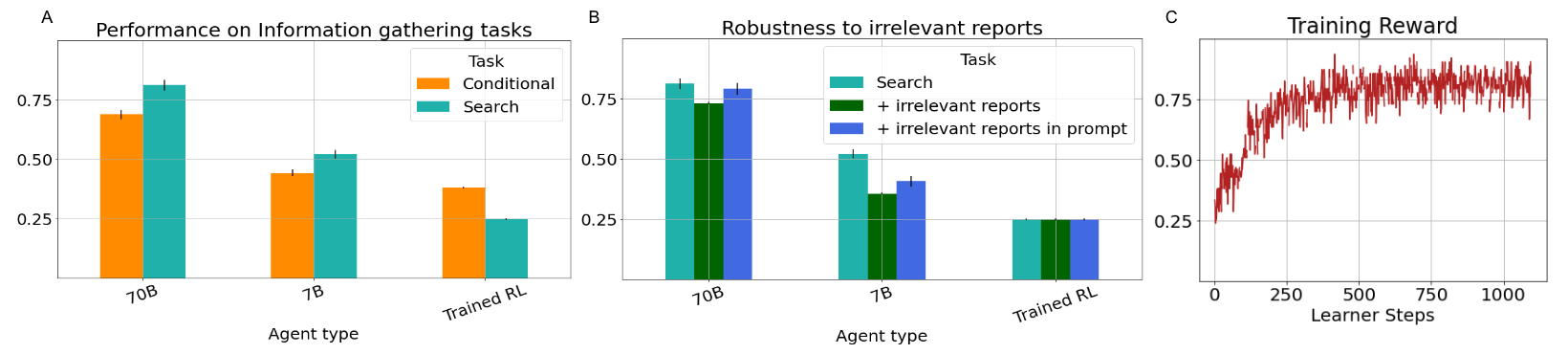
实验结果
研究问题
- RQ1 Planner-Actor-Reporter 系统是否能够在具身环境中实现信息收集任务的零-shot 求解?
- RQ2规划者规模(7B vs 70B)如何影响性能与对 Reporter 不完善的鲁棒性?
- RQ3当 Reporter 不完善时,主要的失效模式是什么,是否可以通过显式提示来缓解?
- RQ4学习型 Reporter 是否通过 RL 提升性能, reducing 对手工反馈的依赖?
- RQ5所提出的任务在逻辑推理、泛化、探索和感知等具身推理方面的测试力度如何?
主要发现
- 70B 规模的 Planner 在信息收集任务上通常比 7B 更易取得成功(例如对应拾取对象的正确推断更好)。
- 纯 RL 基线在秘密属性任务上表现不足,而 Planner-Actor-Reporter 实现了强劲的零-shot 结果。
- 规划者对嘈杂报告具有鲁棒性,70B 在 20% 无关报告的情况下维持比 7B 更好的性能。
- 提供能演示重复性策略的提示可以在 Reports 无关时恢复性能。
- 用 RL 训练 Reporter 可行,且有助于 Planner 学会哪些信息对任务成功最有用。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。