[论文解读] Compact Transformer Tracker with Correlative Masked Modeling
本文提出 CTTrack,一种基于 ViT 的紧凑型跟踪器,具相关掩码解码器以在训练阶段增强特征聚合;实现接近SOTA的性能,同时以 40 fps 运行,相关解码器可移植到其他跟踪器。
Transformer framework has been showing superior performances in visual object tracking for its great strength in information aggregation across the template and search image with the well-known attention mechanism. Most recent advances focus on exploring attention mechanism variants for better information aggregation. We find these schemes are equivalent to or even just a subset of the basic self-attention mechanism. In this paper, we prove that the vanilla self-attention structure is sufficient for information aggregation, and structural adaption is unnecessary. The key is not the attention structure, but how to extract the discriminative feature for tracking and enhance the communication between the target and search image. Based on this finding, we adopt the basic vision transformer (ViT) architecture as our main tracker and concatenate the template and search image for feature embedding. To guide the encoder to capture the invariant feature for tracking, we attach a lightweight correlative masked decoder which reconstructs the original template and search image from the corresponding masked tokens. The correlative masked decoder serves as a plugin for the compact transform tracker and is skipped in inference. Our compact tracker uses the most simple structure which only consists of a ViT backbone and a box head, and can run at 40 fps. Extensive experiments show the proposed compact transform tracker outperforms existing approaches, including advanced attention variants, and demonstrates the sufficiency of self-attention in tracking tasks. Our method achieves state-of-the-art performance on five challenging datasets, along with the VOT2020, UAV123, LaSOT, TrackingNet, and GOT-10k benchmarks. Our project is available at https://github.com/HUSTDML/CTTrack.
研究动机与目标
- 评估在视觉跟踪中,简单的自注意力是否足以进行信息聚合。
- 证明自信息增强在多图注意力中主导跨信息聚合。
- 开发一个轻量级的相关掩码解码器,以在不降低推理速度的前提下训练编码器实现不变特征提取。
- 在多个跟踪基准上展示SOTA性能。
- 提供一个训练时模块,能够在不影响速度的前提下提升其他 Transformer 跟踪器。
提出的方法
- 采用将模板和搜索图像拼接作为输入的普通 Vision Transformer 主干。
- 引入一个相关掩码解码器,包含自解码器和跨解码器,用掩码令牌重建模板和搜索图像。
- 使用多任务损失进行训练,结合 L1、广义 IoU 以及解码器重构损失(掩码令牌的 MSE)。
- 掩码令牌比率设为 75%,以最大化表征学习,灵感来自掩码图像建模(MIM)。
- 推理阶段仅使用 ViT 主干和一个边界框头;解码器仅用于训练。
- 可选地使用一个评分头来更新在线模板,以决定高置信度的更新。
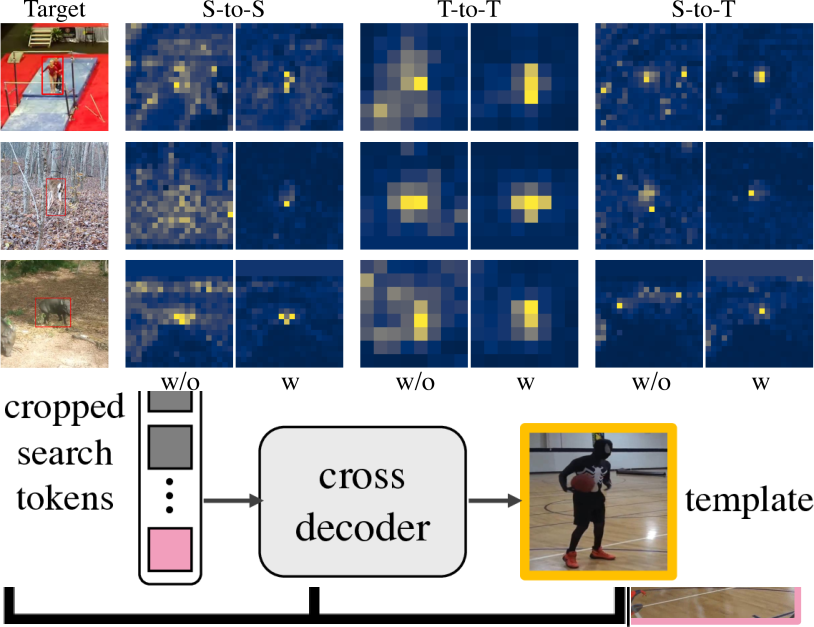
实验结果
研究问题
- RQ1当模板和搜索拼接在一起时,自注意力是否足以进行信息聚合?
- RQ2哪些信息流(模板的自信息、跨信息、搜索的自信息)对跟踪性能贡献最大?
- RQ3相关掩码建模是否能在不降低推理速度的前提下提升 CTTrack?
- RQ4与标准基准上的最先进跟踪器相比,CTTrack 的表现如何?
主要发现
- 作者表明,朴素的自注意力在跟踪中的信息聚合已足够,自信息流相较跨信息流更具影响力。
- CTTrack 以 ViT 主干和简单的边框头实现 40 fps 的速度,同时具有强劲的精度。
- 在 LaSOT 的消融中,CTTrack-L 达到 69.8% AUC 和 76.2% Prec,CTTrack-B 分别为 64.0% AUC 和 67.7% Prec。
- 在各基准上,CTTrack-L 在 UAV123 上达到 71.3% AUC,在 TrackingNet 上达到 84.9% AUC,GOT-10k AO 为 72.8%,体现了具有竞争力的SOTA性能。
- 在 LaSOT 的消融中,加入相关掩码解码后,CTTrack-L 的 AUC 从基线提升至 65.8%,Prec 提升至 70.9%。
- 相关掩码解码器可以集成到其他跟踪器中,以提升性能且不降低推理速度。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。