[论文解读] Comparative Analysis of Generative Models: Enhancing Image Synthesis with VAEs, GANs, and Stable Diffusion
该论文比较 VAEs、GANs 与 Stable Diffusion 在图像合成中的表现,并研究 Grounding DINO 与 Grounded SAM 如何改进 Stable Diffusion 的修复与分割。
This paper examines three major generative modelling frameworks: Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and Stable Diffusion models. VAEs are effective at learning latent representations but frequently yield blurry results. GANs can generate realistic images but face issues such as mode collapse. Stable Diffusion models, while producing high-quality images with strong semantic coherence, are demanding in terms of computational resources. Additionally, the paper explores how incorporating Grounding DINO and Grounded SAM with Stable Diffusion improves image accuracy by utilising sophisticated segmentation and inpainting techniques. The analysis guides on selecting suitable models for various applications and highlights areas for further research.
研究动机与目标
- 评估 Variational Autoencoders (VAEs)、Generative Adversarial Networks (GANs) 与 Stable Diffusion 在图像合成中的优点与局限性。
- 评估扩散式方法如何解决 VAEs(模糊)和 GANs(模式崩溃、不稳定性)中出现的问题。
- 探讨将 Grounding DINO 与 Grounded SAM 与 Stable Diffusion 集成后对分割、修复与上下文一致性的提升。
提出的方法
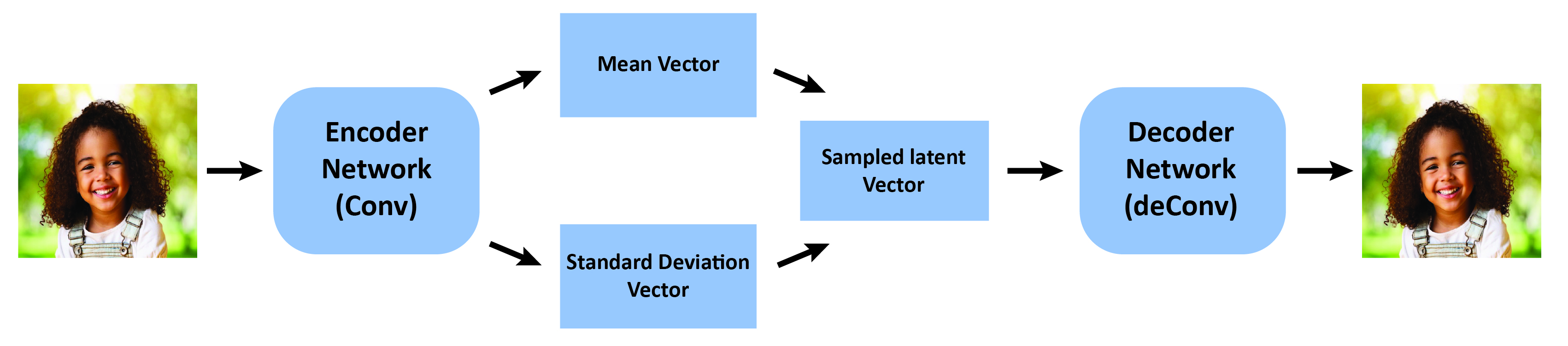
- 将 VAEs 描述为具有重参数化技巧的潜在空间编码/解码器,并讨论其模糊性与后验崩溃。
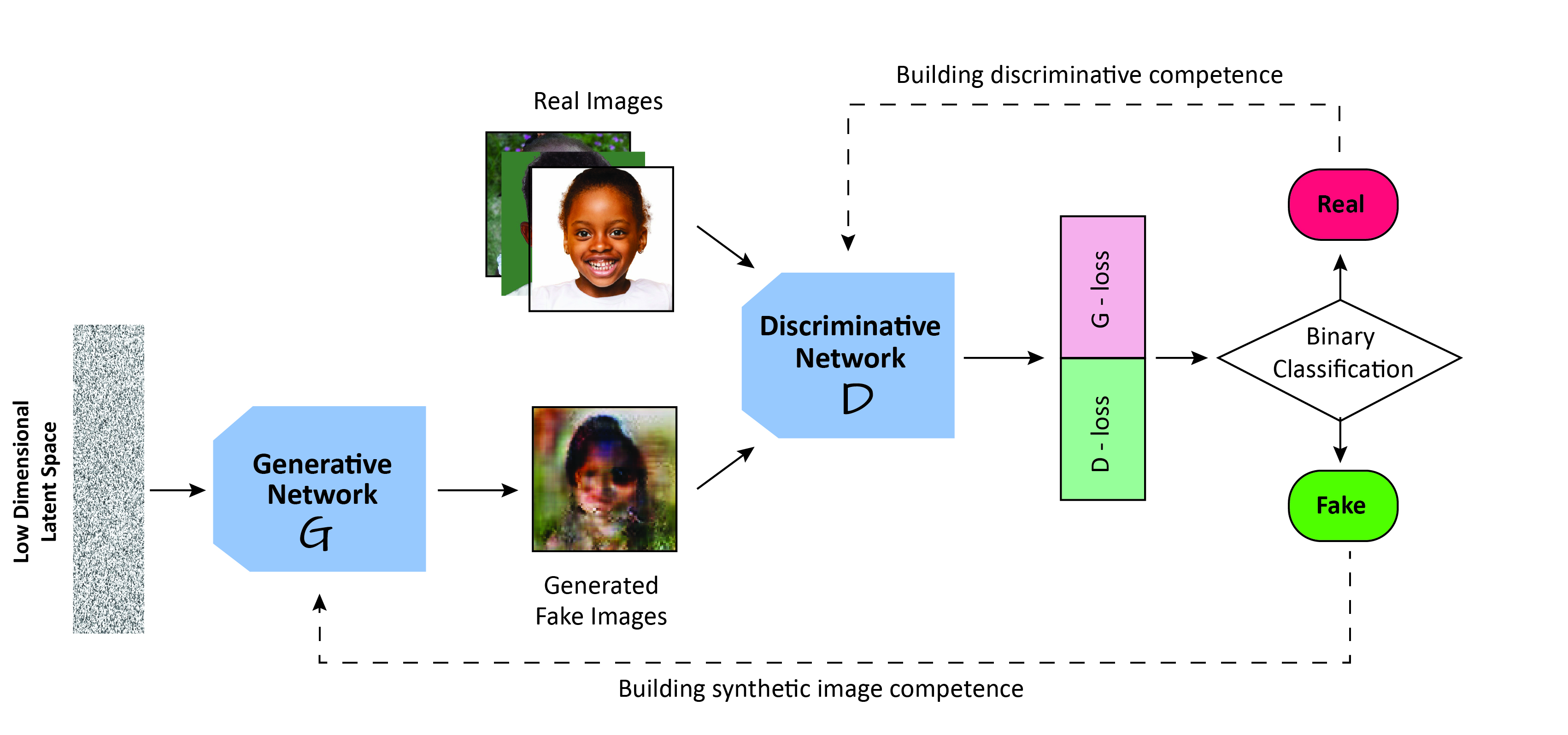
- 概述 GANs 及其生成器–判别器对抗训练,并讨论模式崩溃与训练不稳定性。
- 将 Stable Diffusion 解释为基于扩散的管线,使用 VAE、U-Net 和文本编码器来生成高分辨率、语义上连贯的图像。
- 讨论 Grounding DINO 与 Grounded SAM 与 Stable Diffusion 的整合,以实现精准分割与上下文感知的修复。
实验结果
研究问题
- RQ1在图像合成方面,VAEs、GANs 与 Stable Diffusion 的相对优点与局限性是什么?
- RQ2将 Grounding DINO 与 Grounded SAM 引入 Stable Diffusion 后,在分割与修复方面的性能如何变化?
- RQ3在质量、多样性和计算成本之间的权衡下,哪些应用更适合各自的生成框架?
主要发现
- VAEs 提供高效的潜在空间表示,但通常产生模糊的重建并存在后验崩溃的风险。
- GANs 能提供高质量、真实感强的图像,但存在模式崩溃、训练不稳定和计算成本高的问题。
- Stable Diffusion 能提供高分辨率、多样且语义一致的图像,但推理阶段计算量大且耗时。
- 将 Grounding DINO 与 Grounded SAM 与 Stable Diffusion 集成可提升分割精度与上下文相关的修复,但代价是增加了复杂性和资源需求。
- 讨论强调模型选择应与应用需求相匹配,在质量、多样性和计算考量之间取得平衡。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。