[论文解读] Computing Nonvacuous Generalization Bounds for Deep (Stochastic) Neural Networks with Many More Parameters than Training Data
该论文优化 PAC-Bayes 边界以计算在数百万参数、在成千上万样本上训练的深度随机神经网络的非空泛化界,展示了在过参数化区域的非平凡泛化。
One of the defining properties of deep learning is that models are chosen to have many more parameters than available training data. In light of this capacity for overfitting, it is remarkable that simple algorithms like SGD reliably return solutions with low test error. One roadblock to explaining these phenomena in terms of implicit regularization, structural properties of the solution, and/or easiness of the data is that many learning bounds are quantitatively vacuous when applied to networks learned by SGD in this "deep learning" regime. Logically, in order to explain generalization, we need nonvacuous bounds. We return to an idea by Langford and Caruana (2001), who used PAC-Bayes bounds to compute nonvacuous numerical bounds on generalization error for stochastic two-layer two-hidden-unit neural networks via a sensitivity analysis. By optimizing the PAC-Bayes bound directly, we are able to extend their approach and obtain nonvacuous generalization bounds for deep stochastic neural network classifiers with millions of parameters trained on only tens of thousands of examples. We connect our findings to recent and old work on flat minima and MDL-based explanations of generalization.
研究动机与目标
- Motivate and quantify nonvacuous generalization bounds for deep networks trained with SGD in heavily overparameterized regimes.
- Extend Langford and Caruana’s PAC-Bayes approach to modern deep architectures with millions of parameters.
- Demonstrate that a broad region around SGD solutions contains similarly good models, enabling nonvacuous bounds.
- Connect bounds to ideas on flat minima and MDL-based explanations of generalization.
提出的方法
- Formulate a PAC-Bayes bound for stochastic neural networks and express the bound in terms of a Gaussian distribution over weights with mean w and diagonal covariance s.
- Optimize the bound by gradient-based methods to find a distribution Q = N(w, diag(s)) that minimizes empirical surrogate loss plus a bound-dependent regularizer.
- Use a union-bound style prior over a discretized variance scale lambda to enable a tractable bound and its optimization.
- Employ an unbiased gradient estimate of the surrogate empirical loss under random perturbations of the SGD solution.
- Compute the bound using a Monte Carlo approximation to estimate the empirical error of the randomized classifier and invoke a sample-convergence bound to control estimation error.
- Report results with bounds that hold with high probability (around 0.965) for the tested architectures.
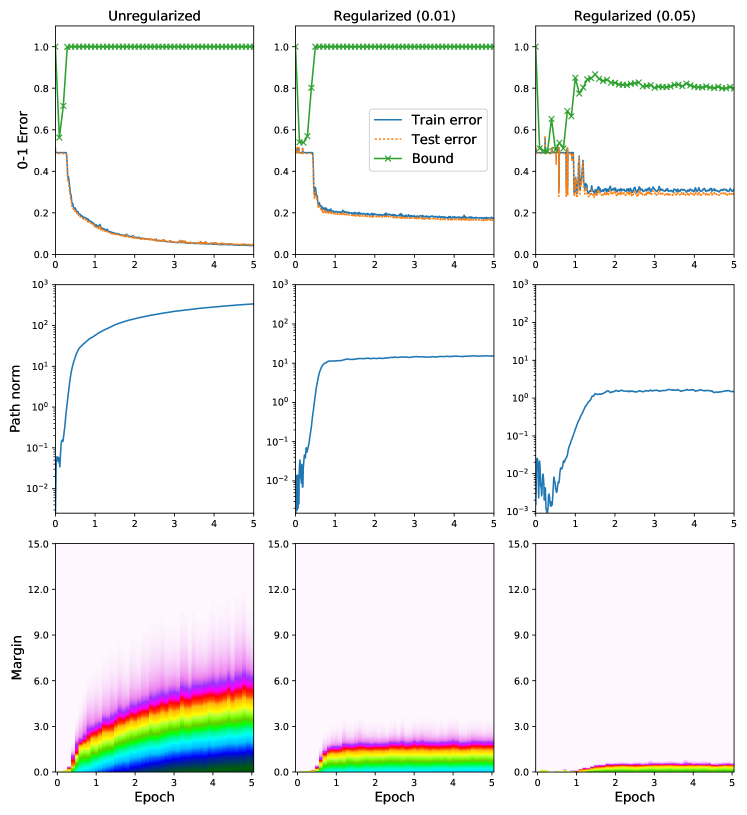
实验结果
研究问题
- RQ1Can nonvacuous generalization bounds be obtained for deep stochastic networks with millions of parameters when training data is relatively scarce?
- RQ2Does optimizing a PAC-Bayes bound around SGD solutions reveal a large region of similarly performing weight configurations (flatness around the solution)?
- RQ3How do data-dependent PAC-Bayes bounds compare to data-independent VC bounds in heavily overparameterized regimes?
- RQ4Do bounds reflect differences between true-label and random-label training scenarios?
主要发现
| 训练误差 | 测试误差 | SNN 训练误差 | SNN 测试误差 | PAC-Bayes 边界 | KL 发散 | # 参数 | VC 维度 |
|---|---|---|---|---|---|---|---|
| 0.001 | 0.018 | 0.028 | 0.034 | 0.161 | 5144 | 471k | 26m |
| 0.002 | 0.018 | 0.027 | 0.035 | 0.179 | 5977 | 943k | 56m |
| 0.000 | 0.015 | 0.027 | 0.034 | 0.170 | 5791 | 326k | 26m |
| 0.000 | 0.016 | 0.028 | 0.033 | 0.186 | 6534 | 832k | 66m |
| 0.000 | 0.015 | 0.029 | 0.035 | 0.223 | 8558 | 2384k | 187m |
| 0.000 | 0.013 | 0.027 | 0.032 | 0.201 | 7861 | 1193k | 121m |
| 0.007 | 0.508 | 0.112 | 0.503 | 1.352 | 201131 | 472k | 26m |
- Nonvacuous numerical bounds on generalization are achievable for deep networks with millions of parameters trained on tens of thousands of examples.
- Optimized PAC-Bayes bounds yield test-error bounds in the range of roughly 16–22% for several architectures on a binary MNIST variant, despite large model capacity.
- For true-label training, the stochastic neural network (SNN) bounds remain nontrivial and do not grow dramatically with larger networks, indicating nontrivial generalization beyond mere parameter-count considerations.
- When trained on random labels, the PAC-Bayes bound becomes vacuous, highlighting the limits of the approach in non-generalizing settings.
- Empirical results show SGD solutions are near the center of a broad region of low-error weight configurations, supporting the hypothesis that flat regions around SGD solutions contribute to generalization.
- KC bounds (VC dimension) remain prohibitively loose for data-independent analysis, underscoring the need for data-dependent approaches like PAC-Bayes.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。