[论文解读] Conformer: Convolution-augmented Transformer for Speech Recognition
Conformer 将卷积与自注意力结合,以建模语音中的本地和全局依赖,在多种参数规模下无语言模型与有语言模型的 LibriSpeech WER 均达到最新水平。
Recently Transformer and Convolution neural network (CNN) based models have shown promising results in Automatic Speech Recognition (ASR), outperforming Recurrent neural networks (RNNs). Transformer models are good at capturing content-based global interactions, while CNNs exploit local features effectively. In this work, we achieve the best of both worlds by studying how to combine convolution neural networks and transformers to model both local and global dependencies of an audio sequence in a parameter-efficient way. To this regard, we propose the convolution-augmented transformer for speech recognition, named Conformer. Conformer significantly outperforms the previous Transformer and CNN based models achieving state-of-the-art accuracies. On the widely used LibriSpeech benchmark, our model achieves WER of 2.1%/4.3% without using a language model and 1.9%/3.9% with an external language model on test/testother. We also observe competitive performance of 2.7%/6.3% with a small model of only 10M parameters.
研究动机与目标
- Motivate end-to-end ASR models to efficiently capture both local and global speech features.
- Propose a Conformer block that fuses convolution and self-attention with Macaron-style feed-forward layers.
- Demonstrate parameter-efficient performance advantages on LibriSpeech across multiple model sizes.
- Analyze design choices (attention heads, kernel sizes, FFN placement) to understand performance gains.
提出的方法
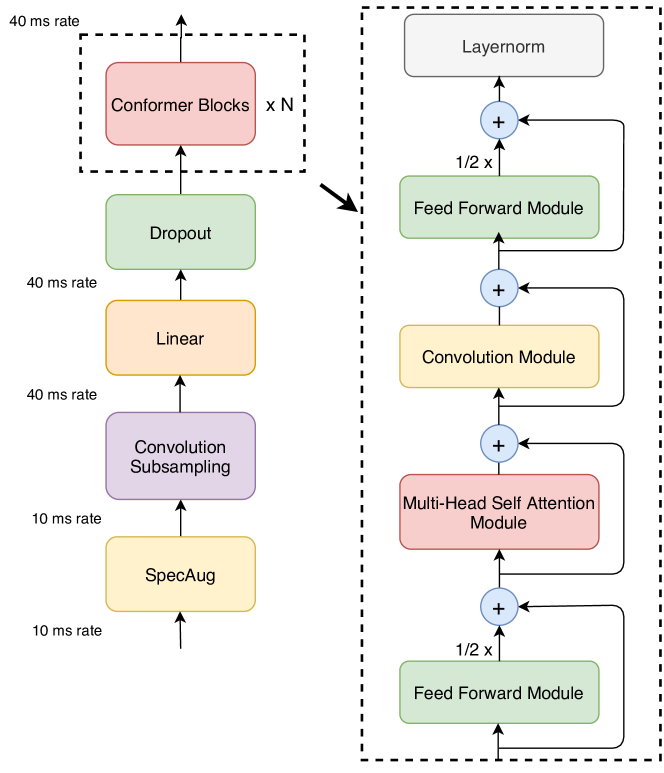
- Introduce Conformer encoder with four sub-blocks: feed-forward, multi-head self-attention, convolution, and second feed-forward.
- Use relative sinusoidal positional encoding in MHSA for length-robustness.
- Implement a convolution module with a gating mechanism (GLU) and depthwise convolution, followed by batch norm and Swish activation.
- Adopt Macaron-Net inspired two half-step FFN modules around MHSA and Convolution with half-step residuals and final layer norm.
- Train with SpecAugment, dropout, variational noise, and Adam optimizer; employ a 3-layer LSTM language model for shallow fusion at decoding.
- Evaluate three model sizes (S, M, L) with 10.3M, 30.7M, and 118.8M parameters on LibriSpeech.
实验结果
研究问题
- RQ1Can convolution-augmented transformers capture both local and global dependencies in speech more efficiently than pure transformers or CNNs?
- RQ2What is the impact of architectural choices (Macaron FFN, convolution-before/after MHSA, kernel size, number of heads) on ASR performance?
- RQ3How does Conformer perform on LibriSpeech across different parameter budgets with and without a language model?
主要发现
| Model | # Params (M) | WER Without LM (test-clean) | WER Without LM (test-other) | WER With LM (test-clean) | WER With LM (test-other) | Notes |
|---|---|---|---|---|---|---|
| Conformer(S) | 10.3 | 2.7 | 6.3 | 2.1 | 5.0 | Dev set and test set results with 10M-parameter regime |
| Conformer(M) | 30.7 | 2.3 | 5.0 | 2.0 | 4.3 | Mid-size model outperforming prior Transformer Transducer |
| Conformer(L) | 118.8 | 2.1 | 4.3 | 1.9 | 3.9 | Large model achieving SOTA on LibriSpeech |
- Conformer achieves state-of-the-art LibriSpeech results across model sizes, e.g., 2.1%/4.3% WER without LM and 1.9%/3.9% with LM for the large model.
- 10.3M (S) model: 2.7% test-clean / 6.3% test-other without LM; 2.1% / 5.0% with LM.
- 30.7M (M) model: 2.3% test-clean / 5.0% test-other without LM; 2.0% / 4.3% with LM.
- 118.8M (L) model: 2.1% test-clean / 4.3% test-other without LM; 1.9% / 3.9% with LM.
- Ablations show convolution sub-block and Macaron FFN pair are critical; placing convolution after MHSA is beneficial; larger kernel sizes (up to 32) improve performance; increasing heads up to 16 improves accuracy on dev sets.

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。