[论文解读] Constrained Deep Networks: Lagrangian Optimization via Log-Barrier Extensions
该论文提出了一种对数障碍扩展方法,用于在无需初始可行解的情况下近似约束深度卷积神经网络中的拉格朗日优化,通过隐式对偶变量实现稳定且精确的训练。该方法在准确率、约束满足度和训练稳定性方面优于惩罚法和显式拉格朗日方法,尤其在高约束负载下表现更优。
This study investigates imposing hard inequality constraints on the outputs of convolutional neural networks (CNN) during training. Several recent works showed that the theoretical and practical advantages of Lagrangian optimization over simple penalties do not materialize in practice when dealing with modern CNNs involving millions of parameters. Therefore, constrained CNNs are typically handled with penalties. We propose *log-barrier extensions*, which approximate Lagrangian optimization of constrained-CNN problems with a sequence of unconstrained losses. Unlike standard interior-point and log-barrier methods, our formulation does not need an initial feasible solution. The proposed extension yields an upper bound on the duality gap -- generalizing the result of standard log-barriers -- and yielding sub-optimality certificates for feasible solutions. While sub-optimality is not guaranteed for non-convex problems, this result shows that log-barrier extensions are a principled way to approximate Lagrangian optimization for constrained CNNs via implicit dual variables. We report weakly supervised image segmentation experiments, with various constraints, showing that our formulation outperforms substantially the existing constrained-CNN methods, in terms of accuracy, constraint satisfaction and training stability, more so when dealing with a large number of constraints.
研究动机与目标
- 解决在弱监督学习中对深度卷积神经网络输出施加硬不等式约束的挑战。
- 克服惩罚法存在的梯度过高和约束满足度差的局限性。
- 消除拉格朗日优化中显式对偶变量更新的需求,后者在深度网络中计算成本高且不稳定。
- 通过使用对数障碍扩展实现隐式对偶变量,为约束卷积神经网络提供一种系统化的无约束优化框架。
- 在处理大量相互竞争的约束时,实现稳定训练与精确的约束满足。
提出的方法
- 引入对数障碍扩展,通过一系列无约束损失近似拉格朗日优化,避免显式对偶变量更新。
- 使用对数障碍惩罚函数对约束违反进行惩罚,将约束卷积神经网络问题形式化。
- 推导出对偶间隙的上界,推广标准对数障碍对偶性结果,为可行解提供次优性证明。
- 使用随机梯度下降(SGD)优化扩展后的损失,使方法与标准深度学习训练流程兼容。
- 将对数障碍公式直接集成到损失函数中,实现端到端训练,无需额外优化循环。
- 通过在损失中嵌入障碍函数,消除对初始可行解的需求,区别于经典内点法。
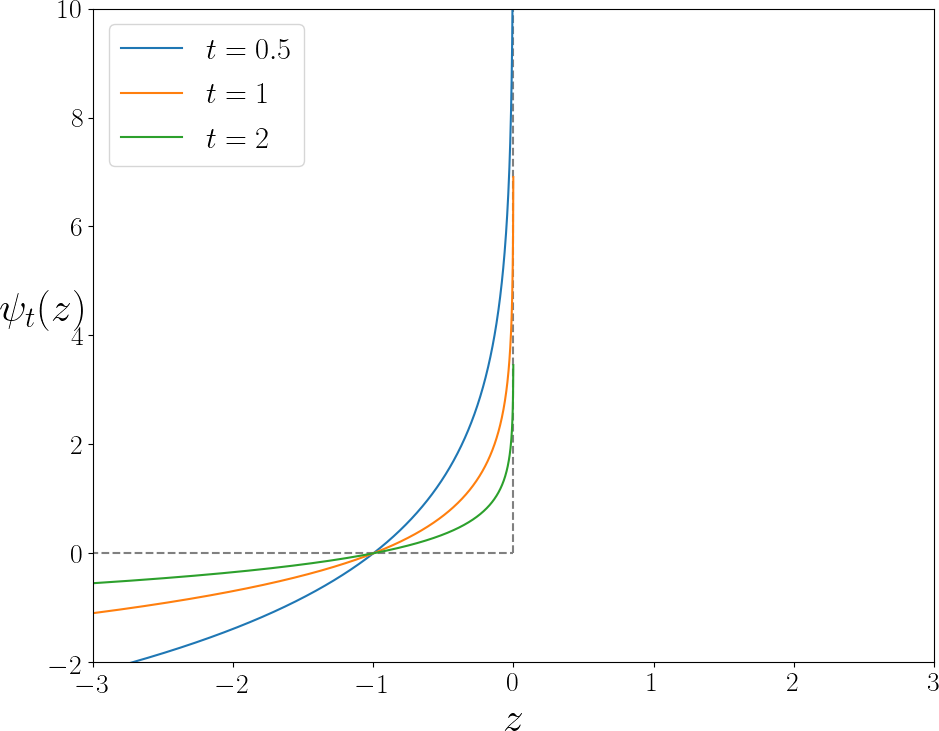
实验结果
研究问题
- RQ1在无需显式对偶变量更新或初始可行解的情况下,对数障碍扩展能否有效近似深度卷积神经网络中的拉格朗日优化?
- RQ2与基于惩罚法和显式拉格朗日法相比,该方法在约束满足度和训练稳定性方面表现如何?
- RQ3在处理大量相互竞争的约束时,该方法是否仍能保持性能与稳定性?
- RQ4对数障碍扩展提供的对偶间隙上界能否作为约束卷积神经网络训练中次优性的证明?
- RQ5在何种场景下,该对数障碍扩展优于现有约束卷积神经网络方法,特别是在弱监督分割任务中?
主要发现
- 在合成数据集上,所提对数障碍扩展方法实现了 0.945 ± 0.001 的平均 Dice 系数(DSC),显著优于标准拉格朗日方法(0.005 ± 0.014)和 ReLU 拉格朗日方法(0.798 ± 0.006)。
- 在 PROMISE12 医学图像分割数据集上,该方法实现了 0.813 ± 0.024 的 DSC,而所有其他方法(包括惩罚法和 ReLU 拉格朗日法)的 DSC 均为 0.000 ± 0.000。
- 该方法是唯一在医学任务中生成非空分割结果的方法,表现出在高约束复杂度下的鲁棒性。
- 如图 4 所示,使用对数障碍扩展训练时,性能和约束满足度在训练周期中均表现出更优的稳定性。
- 该方法仅带来最多 5% 的计算开销,而标准和 ReLU 拉格朗日方法由于对偶变量更新导致计算延迟高达 25%。
- 对偶间隙上界为方法的有效性提供了理论依据,将标准对数障碍对偶性结果推广至约束卷积神经网络。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。