[论文解读] Context Matters: A Strategy to Pre-train Language Model for Science Education
本论文表明在领域内的科学教育数据上对基于 BERT 的模型进行持续预训练可提升对学生科学写作的自动评分,SR2-BERT 和 SR2-SciBERT 在下游任务中取得最佳结果。
This study aims at improving the performance of scoring student responses in science education automatically. BERT-based language models have shown significant superiority over traditional NLP models in various language-related tasks. However, science writing of students, including argumentation and explanation, is domain-specific. In addition, the language used by students is different from the language in journals and Wikipedia, which are training sources of BERT and its existing variants. All these suggest that a domain-specific model pre-trained using science education data may improve model performance. However, the ideal type of data to contextualize pre-trained language model and improve the performance in automatically scoring student written responses remains unclear. Therefore, we employ different data in this study to contextualize both BERT and SciBERT models and compare their performance on automatic scoring of assessment tasks for scientific argumentation. We use three datasets to pre-train the model: 1) journal articles in science education, 2) a large dataset of students' written responses (sample size over 50,000), and 3) a small dataset of students' written responses of scientific argumentation tasks. Our experimental results show that in-domain training corpora constructed from science questions and responses improve language model performance on a wide variety of downstream tasks. Our study confirms the effectiveness of continual pre-training on domain-specific data in the education domain and demonstrates a generalizable strategy for automating science education tasks with high accuracy. We plan to release our data and SciEdBERT models for public use and community engagement.
研究动机与目标
- 推动对学生科学文字的自动评分并减少教师标注工作量。
- 研究领域特定预训练数据是否提高在科学教育任务中基于 BERT 的模型性能。
- 比较在域内语境化策略在 BERT 与 SciBERT 变体之间的差异。
- 证明对学生回答进行持续预训练在下游评分任务中的有效性。
- 提供可扩展的方法并发布 SciEdBERT 模型供社区使用。
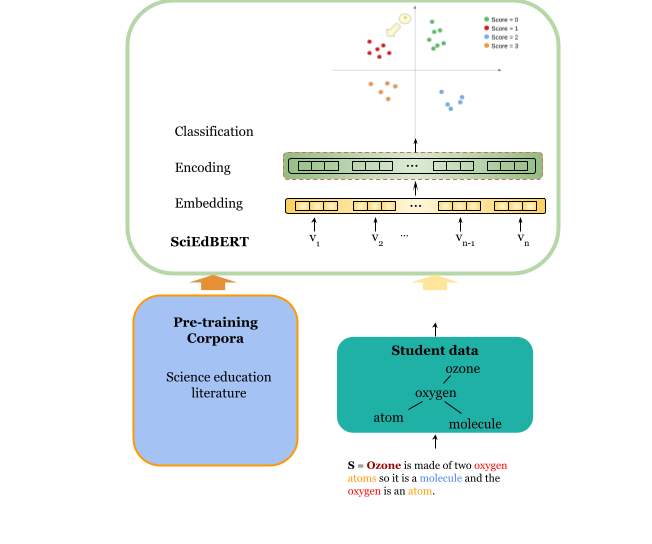
提出的方法
- 在微调前,使用金字塔式训练方案将预训练模型以域内数据进行上下文化。
- 在三个数据源上对模型进行预训练:SciEdJ(科学教育期刊)、SR1(5万+ 学生回答)、SR2(科学论证回答)。
- 在下游任务上微调,使用7T(来自 SR1 的七个任务)和 4T(SR2 任务)。
- 将基线 BERT 与 SR1-BERT 及额外变体(包括 SciBERT、SciEdJ-BERT、SciEdJ-SciBERT、SR2-BERT 和 SR2-SciBERT)进行比较,以评估上下文化的影响。
- 使用多个构造性回答任务的任务级准确率来评估性能。
- 采用持续预训练机制以最大化预训练数据与下游任务之间的一致性。
实验结果
研究问题
- RQ1领域内的持续预训练是否相对通用 BERT 基线提升自动评分准确性?
- RQ2在 SciEdJ、SR1、SR2 的上下文化对科学教育评分任务的模型性能有何影响?
- RQ3哪种模型变体(BERT vs SciBERT,使用不同领域数据)在构造性回答的下游准确性方面表现最佳?
- RQ4在对具体评分任务进行微调之前,先在与任务相关的语境上进行训练是否有帮助?
主要发现
| 表 1 - 7T 任务准确度按模型 | 表 2 - 4T 任务准确度按模型 | ||||
|---|---|---|---|---|---|
| H4-2 | 0.913 | 0.929 | |||
| H4-3 | 0.831 | 0.831 | |||
| H5-2 | 0.958 | 0.970 | |||
| J2-2 | 0.920 | 0.926 | |||
| J6-2 | 0.959 | 0.973 | |||
| J6-3 | 0.845 | 0.845 | |||
| R1-2 | 0.864 | 0.864 | |||
| Average | 0.904 | 0.912 | |||
| Table 2 G4 | 0.792 | 0.804 | 0.815 | 0.821 | 0.815 |
| G6 | 0.766 | 0.727 | 0.742 | 0.719 | 0.766 |
| S2 | 0.895 | 0.882 | 0.889 | 0.915 | 0.928 |
| S3 | 0.934 | 0.954 | 0.921 | 0.954 | 0.954 |
- SR1-BERT 平均而言略强于基线 BERT(0.912 对 0.904)。
- SR2-SciBERT 在 4T 任务上达到最高平均准确度(0.866)。
- SR2-BERT 也表现强劲(0.852 的平均值),在各个具体任务上往往可以达到或超过 SciEdJ 变体。
- 用下游任务语言(SR2)对模型进行情境化比仅使用更广泛的领域语言能获得更好的单任务表现。
- 在评估模型中,SciEdJ-SciBERT 和 SciEdJ-BERT 平均表现最差,暗示仅科学教育领域出版物可能会混淆学生写作语言。
- 总体而言,对领域特定数据进行持续预训练,特别是与下游任务对齐时,提升了对学生科学写作的自动评分。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。