[论文解读] Contextuality and inductive bias in quantum machine learning
本论文提出一个将量子上下文性与机器学习中的归纳偏置联系起来的一般框架,定义上下文性多任务模型,并表明上下文性可以提升表达能力,在一个玩具设置中,量子模型通过编码线性守恒的标签偏置在某些情况下可超越经典代理模型。
Generalisation in machine learning often relies on the ability to encode structures present in data into an inductive bias of the model class. To understand the power of quantum machine learning, it is therefore crucial to identify the types of data structures that lend themselves naturally to quantum models. In this work we look to quantum contextuality -- a form of nonclassicality with links to computational advantage -- for answers to this question. We introduce a framework for studying contextuality in machine learning, which leads us to a definition of what it means for a learning model to be contextual. From this, we connect a central concept of contextuality, called operational equivalence, to the ability of a model to encode a linearly conserved quantity in its label space. A consequence of this connection is that contextuality is tied to expressivity: contextual model classes that encode the inductive bias are generally more expressive than their noncontextual counterparts. To demonstrate this, we construct an explicit toy learning problem -- based on learning the payoff behaviour of a zero-sum game -- for which this is the case. By leveraging tools from geometric quantum machine learning, we then describe how to construct quantum learning models with the associated inductive bias, and show through our toy problem that they outperform their corresponding classical surrogate models. This suggests that understanding learning problems of this form may lead to useful insights about the power of quantum machine learning.
研究动机与目标
- 激发寻找自然能够利用量子归纳偏置的数据结构。
- 为机器学习中的广义上下文性定义框架,并提出上下文学习模型的概念。
- 将上下文性、运算等价性和归纳偏置联系到表达能力和学习性能。
- 识别在上下文性限制非上下文性模型且可能需要量子方法的数据配置。
- 通过一个玩具问题演示编码该偏置的量子模型如何在表现上超越经典代理。
提出的方法
- 为学习模型引入广义上下文性框架(操作统计、制备、效应)。
- 为多任务学习定义操作场景,并通过本体模型形式化非上下文性。
- 建立一个主要结果,将标签空间中的线性守恒偏置与非上下文性可学习分布的约束联系起来。
- 描述两种量子-设定(ansatz)方案来编码归纳偏置:基于状态的方法和基于测量的方法。
- 构建一个玩具石头剪子布学习问题以证明非上下文性模型的表达能力上限。
- 使用几何量子机器学习工具设计与偏置对齐的量子模型,并与经典代理进行比较。
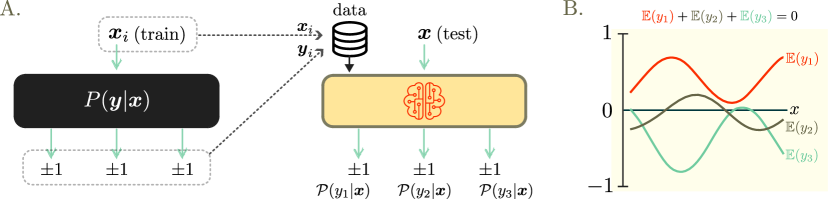
实验结果
研究问题
- RQ1什么是适合机器学习中学习模型的上下文性 notions?
- RQ2对标签空间进行线性守恒律编码的归纳偏置如何影响非上下文性模型的表达能力?
- RQ3在结构化任务上,基于上下文性的量子模型的归纳偏置是否能带来优于经典代理的泛化?
- RQ4在哪些学习情景中,上下文性启发的偏置成为准确学习的必要资源?
主要发现
- 上下文性与表达能力相关:编码归纳偏置的上下文性模型类往往比非上下文性模型更具表达能力。
- 标签空间中的线性守恒量会带来运算等价性,限制非上下文性模型,可能限制泛化。
- 一个玩具石头剪子布问题对非上下文性模型在学习收益行为方面的表达能力给出精确界限。
- 通过状态结构或测量设计编码偏置的量子学习模型在玩具任务上可以超越相应的经典代理模型。
- 数值证据表明,在正则化下,具有上下文性启发偏置的量子模型达到的泛化误差低于经典代理。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。