[论文解读] Continual Pre-training of Language Models
提出 DAS,一种基于软掩蔽的持续领域自适应预训练方法,使语言模型能够从一系列无标注领域语料中学习,同时减轻遗忘并实现知识迁移。
Language models (LMs) have been instrumental for the rapid advance of natural language processing. This paper studies continual pre-training of LMs, in particular, continual domain-adaptive pre-training (or continual DAP-training). Existing research has shown that further pre-training an LM using a domain corpus to adapt the LM to the domain can improve the end-task performance in the domain. This paper proposes a novel method to continually DAP-train an LM with a sequence of unlabeled domain corpora to adapt the LM to these domains to improve their end-task performances. The key novelty of our method is a soft-masking mechanism that directly controls the update to the LM. A novel proxy is also proposed to preserve the general knowledge in the original LM. Additionally, it contrasts the representations of the previously learned domain knowledge (including the general knowledge in the pre-trained LM) and the knowledge from the current full network to achieve knowledge integration. The method not only overcomes catastrophic forgetting, but also achieves knowledge transfer to improve end-task performances. Empirical evaluation demonstrates the effectiveness of the proposed method.
研究动机与目标
- 研究面对一系列无标注领域语料时语言模型的持续领域自适应预训练(持续 DAP 训练)。
- 开发一种在实现跨领域知识迁移的同时防止灾难性遗忘的方法。
- 在没有访问预训练数据的情况下,通过一个单元重要性 proxy 指标来保留通用 LM 知识。
- 通过对比信号推动将新领域知识与先前学习的知识整合。
- 在多个无标注领域语料和最终任务分类任务上评估该方法。
提出的方法
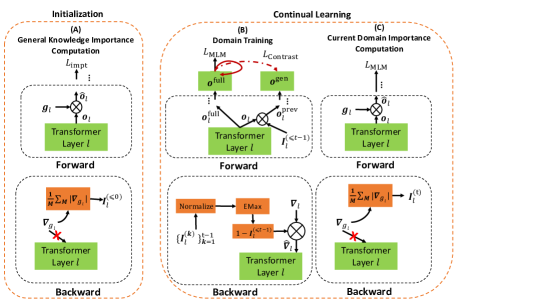
- 引入一种软掩蔽机制,利用单元级重要性在持续 DAP 训练期间约束向后梯度。
- 定义基于代理 KL 散度的鲁棒性损失,用于在没有访问预训练数据的情况下估计通用 LM 知识的单元重要性。
- 在跨领域累积单元重要性,使用逐元素最大值,并在向后传播中应用软掩蔽,以在学习新领域的同时保留过去知识。
- 使用对比损失,鼓励累积的(过去的)知识与完整的(过去+当前)知识之间的互补表征,以促进知识整合。
- 在训练每个领域后计算当前领域的单元重要性,并更新下一个领域的累积重要性。
- 最终任务微调不需要领域 ID,因为 LM 保留了所有整合的知识。
实验结果
研究问题
- RQ1持续领域自适应预训练是否能够通过对整个 LM 的更新而非参数隔离来有效实现?
- RQ2在持续 DAP 训练中,如何在实现跨领域知识迁移的同时防止灾难性遗忘?
- RQ3在单元重要性引导的软掩蔽机制下,是否能保护通用 LM 知识并支持跨域迁移?
- RQ4对比学习目标是否能够改善过去领域知识与当前领域知识之间的整合?
- RQ5在没有访问原始预训练数据的代理基准下,基于代理的单元重要性度量是否足以初始化通用知识保留?
主要发现
- DAS 在跨多个领域的最终任务分类上超越了广泛的基线。
- DAS 实现了强大的知识迁移和负向遗忘率,表明有效的遗忘防护和跨域迁移。
- 在持续设置中,直接的全 LM 领域学习(如 DAS)优于适配器和提示为主的领域自适配基线。
- 对比完整知识与过去知识的对比目标在知识整合方面优于仅对过去知识的对比。
- 基于代理的 KL 散度衡量可以在没有原始预训练数据的情况下有效估计通用知识的单元重要性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。