[论文解读] Contrast, Attend and Diffuse to Decode High-Resolution Images from Brain Activities
本文提出一个两阶段的 fMRI 表征学习框架(DC-MAE 预训练 + 跨模态微调),以条件化潜在扩散模型从脑活动中高分辨率图像重建,相较于前方法取得显著提升。
Decoding visual stimuli from neural responses recorded by functional Magnetic Resonance Imaging (fMRI) presents an intriguing intersection between cognitive neuroscience and machine learning, promising advancements in understanding human visual perception and building non-invasive brain-machine interfaces. However, the task is challenging due to the noisy nature of fMRI signals and the intricate pattern of brain visual representations. To mitigate these challenges, we introduce a two-phase fMRI representation learning framework. The first phase pre-trains an fMRI feature learner with a proposed Double-contrastive Mask Auto-encoder to learn denoised representations. The second phase tunes the feature learner to attend to neural activation patterns most informative for visual reconstruction with guidance from an image auto-encoder. The optimized fMRI feature learner then conditions a latent diffusion model to reconstruct image stimuli from brain activities. Experimental results demonstrate our model's superiority in generating high-resolution and semantically accurate images, substantially exceeding previous state-of-the-art methods by 39.34% in the 50-way-top-1 semantic classification accuracy. Our research invites further exploration of the decoding task's potential and contributes to the development of non-invasive brain-machine interfaces.
研究动机与目标
- 去噪并净化脑 fMRI 表征以提高解码质量。
- 利用跨模态引导关注与视觉相关的脑信号。
- 整合一个潜在扩散模型以从 fMRI 生成高分辨率的语义上真实的图像。
- 在 GOD 和 BOLD5000 数据集上相比基线,展示更优的重构性能。
提出的方法
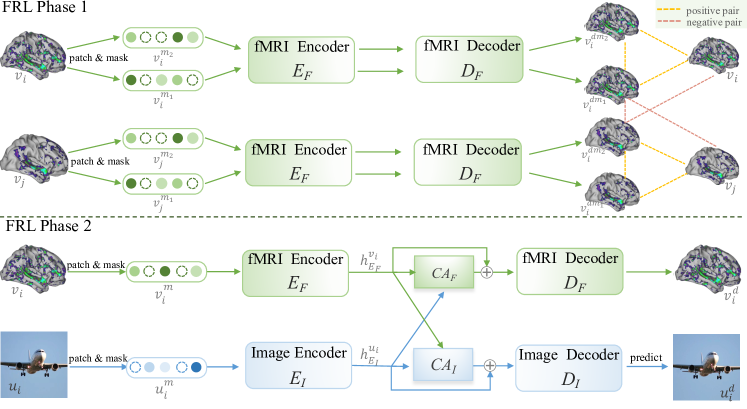
- 在未标注的 fMRI 数据上使用 Double-contrastive Masked Auto-Encoder (DC-MAE) 预训练一个 fMRI 特征学习器,以学习去噪表示。
- 阶段 2 使用带有跨注意力的图像自编码器对 fMRI 编码器进行微调,以引导对有信息的脑模式进行重建的关注。
- 用优化后的 fMRI 编码器为潜在扩散模型(LDM)提供条件,从脑活动生成图像。
- 使用带有跨注意力条件的微调 LDM,结合 fMRI 特征进行条件图像生成。
- 使用基于通过预训练的 ImageNet 分类器对 50-way-top-1 语义正确性进行评估的评估指标。
实验结果
研究问题
- RQ1DC-MAE 是否能够有效去噪并跨个体对齐 fMRI 表征?
- RQ2fMRI 与图像自编码器之间的跨模态引导是否能提升从 fMRI 的视觉重建?
- RQ3以 fMRI 条件化的潜在扩散模型在生成高分辨率、语义上准确的图像方面的表现如何?
- RQ4FRL 第 2 阶段的重建损失和掩码比率在解码性能中的相对贡献有哪些?
- RQ5所提框架是否可扩展到如 GOD 和 BOLD5000 这样的数据集?
主要发现
- 所提出的模型在 GOD 和 BOLD5000 数据上的 50-way-top-1 准确率比以往的最先进方法提升了 39.34%。
- 两阶段的 FRL(DC-MAE 预训练后接跨模态微调)实现了高分辨率且语义上准确的重建。
- 消融研究显示联合的 fMRI 和图像重建损失、以及精心选择的掩码比率和解码器深度对性能至关重要。
- 该方法在 GOD 的 CSI1 被测对象的 50-way-top-1 准确率达到 25,并在测试集 fMRI 数据未用于微调时,对 GOD 的其他对象 1、2、4、5 显示优于 DC-LDM。
- 该方法识别出偏置与细节重建之间的权衡,承认数据集在 LDM 训练中的偏差。
![Figure 2: [a] Demo of the forward and backward processes of the diffusion model. [b] The forward process of the diffusion model which progressively corrupts an image with Gaussian noise. [c] In the backward process, the diffusion model, conditioned on our pretrained fMRI encoder, gradually denoises](https://ar5iv.labs.arxiv.org/html/2305.17214/assets/x2.png)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。