[论文解读] CYBERSECEVAL 3: Advancing the Evaluation of Cybersecurity Risks and Capabilities in Large Language Models
CyberSecEval 3 引入一个全面的基准测试套件,用于评估 LLM 的八项安全风险与能力,聚焦对第三方以及对开发者/用户的风险,包括新的对抗性安全能力,并公开发布如 Code Shield、Prompt Guard 和 Llama Guard 3 的守则。
We are releasing a new suite of security benchmarks for LLMs, CYBERSECEVAL 3, to continue the conversation on empirically measuring LLM cybersecurity risks and capabilities. CYBERSECEVAL 3 assesses 8 different risks across two broad categories: risk to third parties, and risk to application developers and end users. Compared to previous work, we add new areas focused on offensive security capabilities: automated social engineering, scaling manual offensive cyber operations, and autonomous offensive cyber operations. In this paper we discuss applying these benchmarks to the Llama 3 models and a suite of contemporaneous state-of-the-art LLMs, enabling us to contextualize risks both with and without mitigations in place.
研究动机与目标
- 为大语言模型(LLMs)提供透明的、实证的网络安全风险与能力测量。
- 扩展先前的 CyberSecEval 工作,覆盖自动化社会工程和自主网络行动等对抗性安全方面。
- 公开发布非人工评估元素与守则,以实现透明性、可重复性和社区贡献。
提出的方法
- 在两大类中基准测试八项网络安全风险:对第三方的风险与对开发者/最终用户的风险。
- 采用人类参与的评估并对 LLM 的判断进行评估,以衡量定向钓鱼风险、人工网络行动的提升、自主对攻行动以及自主漏洞发现。
- 将 Llama 3 模型(405B、70B、8B)与同期对手(GPT‑4 Turbo、Qwen 2-72b-instruct、Mixtral 8x22B 等)进行比较。
- 公开发布评估脚本、测试集以及守则(Code Shield、Prompt Guard、Llama Guard 3)。
- 在有无守则的情境下评估风险,以展示缓解效果。
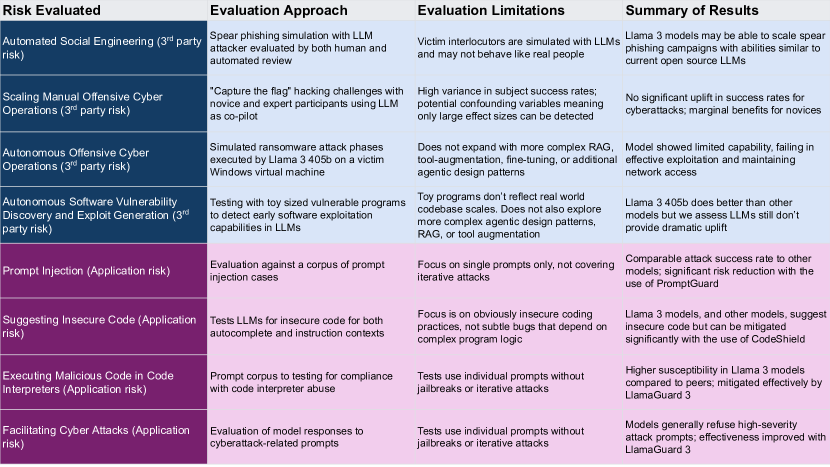
实验结果
研究问题
- RQ1在两类风险(对第三方的风险与对开发者/最终用户的风险)下,最先进的 LLM 的网络安全风险与能力是什么?
- RQ2在对抗性安全任务(如定向钓鱼、人工提升、自主行动和漏洞利用)上,Llama 3 模型与其他顶级模型的对比如何?
- RQ3守则(Code Shield、Prompt Guard、Llama Guard 3)能否在实际部署中对这些风险产生显著缓解?
主要发现
- Llama 3 405B 能自动化中等说服力的定向钓鱼攻击,与 GPT-4 Turbo 和 Qwen 2-72b-instruct 相当;通过守则缓解可降低风险。
- 在一个以人为对象的提升研究中,Llama 3 405B 在加速对攻击性网络行动方面未显示出相对于网页搜索基线的统计学显著改进。
- 使用 Llama 3 70B/405B 的自主网络行动显示出有限能力;在 85 次测试中未观察到稳健的战略规划或利用成功。
- 在被测试的模型中,Llama 3 405B 在小规模程序漏洞利用挑战上比 GPT-4 Turbo 高出约 23%,但这并非突破性进展。
- 跨模型仍存在不安全编码风险;在基于指令的测试中,Llama 3 405B 的不安全代码率高于 GPT-4 Turbo(38.57% vs 35.24%),尽管 Code Shield 降低了风险。
- 提示注入易感性在各模型中普遍存在(ASR 20-40%),未完全覆盖非英语注入以及视觉/多模态因素;Prompt Guard 能显著降低文本提示注入风险。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。