[论文解读] D4: Improving LLM Pretraining via Document De-Duplication and Diversification
该论文提出 D4,一种结合 SemDeDup 去重与聚类式多样化的数据选择方法,以提升 LLM 预训练效率和下游准确性,并在模型规模达到 6.7B 参数时显示出收益。
Over recent years, an increasing amount of compute and data has been poured into training large language models (LLMs), usually by doing one-pass learning on as many tokens as possible randomly selected from large-scale web corpora. While training on ever-larger portions of the internet leads to consistent performance improvements, the size of these improvements diminishes with scale, and there has been little work exploring the effect of data selection on pre-training and downstream performance beyond simple de-duplication methods such as MinHash. Here, we show that careful data selection (on top of de-duplicated data) via pre-trained model embeddings can speed up training (20% efficiency gains) and improves average downstream accuracy on 16 NLP tasks (up to 2%) at the 6.7B model scale. Furthermore, we show that repeating data intelligently consistently outperforms baseline training (while repeating random data performs worse than baseline training). Our results indicate that clever data selection can significantly improve LLM pre-training, calls into question the common practice of training for a single epoch on as much data as possible, and demonstrates a path to keep improving our models past the limits of randomly sampling web data.
研究动机与目标
- 在 LLM 预训练中,超越简单去重,推动数据选择以提升效率和性能。
- 研究基于嵌入的策略,以减少重复驱动的聚类并使训练数据多样化。
- 在固定计算预算和数据受限的情况下,量化多种模型规模下的效率和性能提升。
- 质疑用单次遍历在尽可能大的数据集上训练总是最优的观点。
提出的方法
- 使用一个125M参数的模型对文档进行嵌入,以获得最后一个标记的嵌入向量。
- 在嵌入空间中应用 SemDeDup 以去除近重复项。
- 对去重后的数据进行 K-Means 聚类,并应用 SSL Prototypes 以选择多样化样本。
- 提出 D4,将去重与多样化结合起来,总体选择比率为 R = R_dedup * R_proto。
- 在固定计算和数据受限场景下,对 1.3B 与 6.7B 参数的 OPT 模型进行评估,训练到 40B–100B 令牌。
- 在 16 个 NLP 任务和困惑度指标上计算效率提升和下游性能。
实验结果
研究问题
- RQ1基于嵌入的数据选择(SemDeDup 与多样化)是否在 LLM 预训练中相对于随机采样和简单去重提高了效率?
- RQ2两阶段选择(先去重再基于聚类的多样化)是否可以缓解重复驱动的聚类问题,并带来更好的困惑度和下游准确性?
- RQ3在固定计算和数据受限条件下,数据选择的收益如何随模型大小和令牌预算扩大?
- RQ4在 web-snapshot 与非 web-snapshot 验证集上的数据选择权衡是什么?
主要发现
| S | T_total | T_selected | Epochs | 非网页快照 PPL | 指令 + 答案 PPL |
|---|---|---|---|---|---|
| Random | 40B | 40B | 1 | 16.27±0.012 | 14.19±0.003 |
| 40B | 20B | 2 | 16.39±0.011 | 14.37±0.015 | |
| D4 | 40B | 20B | 2 | 16.10±0.024 | 13.85±0.016 |
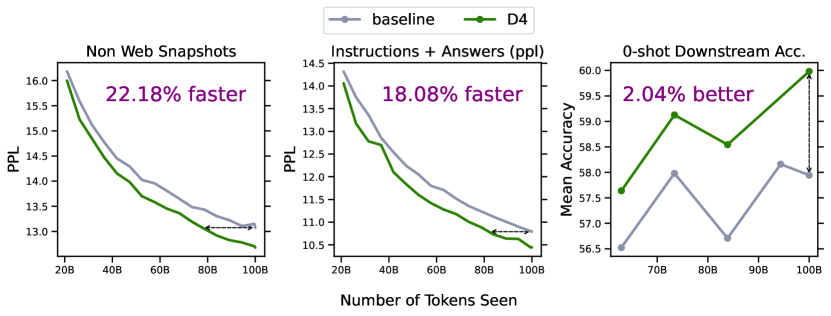
- 在 6.7B 规模下,D4 在困惑度方面带来约 18-20% 的效率提升,且下游准确性平均提升约 2%。
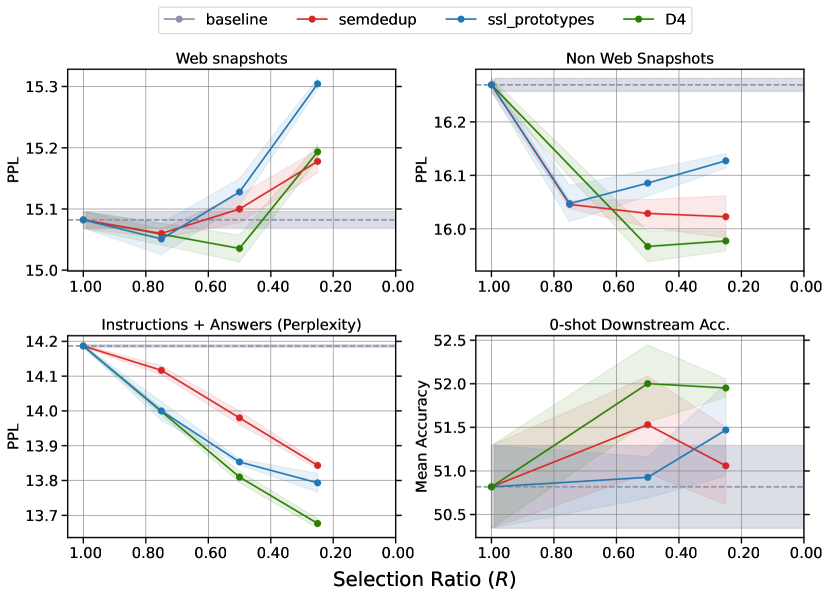
- D4 的表现优于单独使用 SemDeDup 或 SSL Prototypes。
- 在固定数据条件下,重复选择的样本数据(通过 D4)可以优于使用新随机数据令牌进行训练。
- 在固定计算场景下,使用更大规模的去重/多样化子集进行训练可在减少约 20% 更新次数的同时达到等效困惑度。
- 在 SemDeDup 与 SSL Prototypes 之间重新聚类对于减少重复驱动的聚类并提升性能至关重要。
- 成本分析表明,D4 的总体效率提升随模型规模增大而增长,对于更大的模型,潜在提升约 20–22%。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。