[论文解读] DatasetDM: Synthesizing Data with Perception Annotations Using Diffusion Models
DatasetDM 提出一种文本到数据的范式,使用感知解码器从扩散模型潜在编码中提取像素级注释,从而仅需 ~100 张真实图像来训练解码器即可获得无限合成标注数据。
Current deep networks are very data-hungry and benefit from training on largescale datasets, which are often time-consuming to collect and annotate. By contrast, synthetic data can be generated infinitely using generative models such as DALL-E and diffusion models, with minimal effort and cost. In this paper, we present DatasetDM, a generic dataset generation model that can produce diverse synthetic images and the corresponding high-quality perception annotations (e.g., segmentation masks, and depth). Our method builds upon the pre-trained diffusion model and extends text-guided image synthesis to perception data generation. We show that the rich latent code of the diffusion model can be effectively decoded as accurate perception annotations using a decoder module. Training the decoder only needs less than 1% (around 100 images) manually labeled images, enabling the generation of an infinitely large annotated dataset. Then these synthetic data can be used for training various perception models for downstream tasks. To showcase the power of the proposed approach, we generate datasets with rich dense pixel-wise labels for a wide range of downstream tasks, including semantic segmentation, instance segmentation, and depth estimation. Notably, it achieves 1) state-of-the-art results on semantic segmentation and instance segmentation; 2) significantly more robust on domain generalization than using the real data alone; and state-of-the-art results in zero-shot segmentation setting; and 3) flexibility for efficient application and novel task composition (e.g., image editing). The project website and code can be found at https://weijiawu.github.io/DatasetDM_page/ and https://github.com/showlab/DatasetDM, respectively
研究动机与目标
- 推动在感知任务中对大规模标注数据的需求并降低标注成本。
- 提出一个通用框架,将扩散潜在编码解码为多任务的感知注释。
- 利用扩散反演和统一的 P-Decoder,使文本引导的数据生成可用于多样化数据集。
- 证明合成数据在分割、深度和姿态任务中可以达到最先进或具有竞争力的结果。
提出的方法
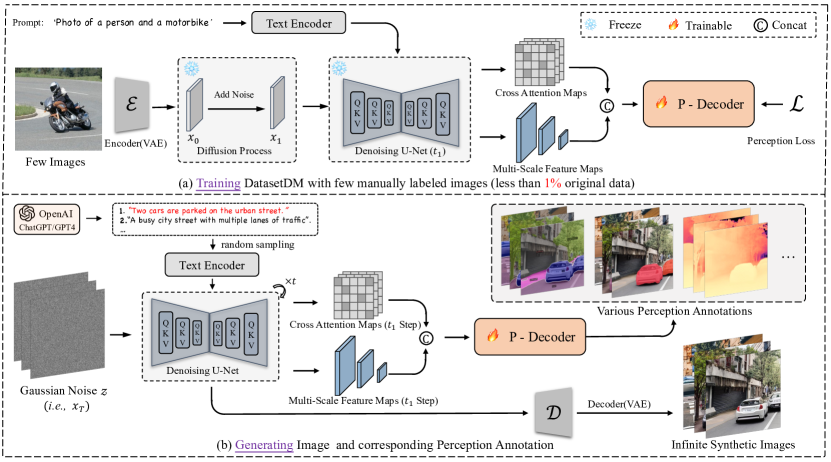
- 使用扩散反演从真实图像中提取潜在编码,并将多尺度扩散特征与交叉注意力图融合,形成超列表征。
- 开发一个通用的感知解码器(P-Decoder),在基于变换器的架构中将融合的扩散表示转换为各种感知注释(如掩码、深度、关键点)。
- 使用少于 1% 的真实标注,通过视觉对齐/指令微调方法提高输出跟随能力来训练 P-Decoder。
- 利用 GPT-4 进行文本引导的数据生成,产生多样化提示,打造广泛且开放的合成数据流水线。
- 在数据合成过程中保持扩散模型权重固定,并使用潜在编码反演加解码器来生成合成注释,从而实现无限标注数据。
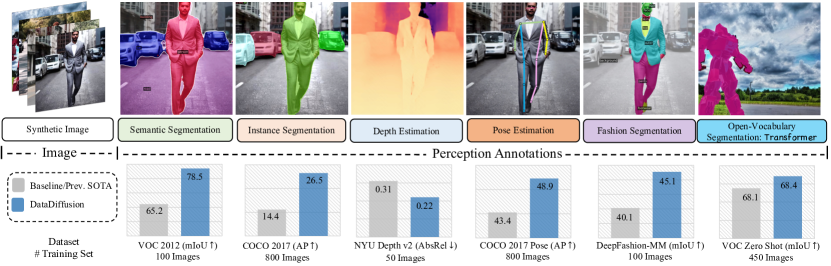
实验结果
研究问题
- RQ1统一的感知解码器是否能够解码扩散潜在编码以在多任务上产生准确的感知注释?
- RQ2训练该解码器需要多少真实标注数据以实现无限的合成、带注释的数据?
- RQ3以扩散模型进行文本引导的数据生成是否提升下游感知任务(语义分割、实例分割、深度估计和姿态估计)?
- RQ4扩 diffusion 时间步长、交叉注意力融合和提示多样性对合成注释的质量和实用性有何影响?
主要发现
- DatasetDM 生成的合成数据在多任务上显著提升,例如在 VOC 2012 语义分割上实现 13.3% 的 mIoU 增益,在 COCO 2017 实例分割上实现 12.1% 的 AP 增益。
- 仅使用 100 张真实图像配合合成数据,VOC 2012 的 mIoU 达到 78.5%(表 2 的真实数据仅基线为 65.2%)。
- 在 COCO2017 的实例分割上,使用 800 张真实图像和 80k 的合成图像实现 26.5 的 AP(来自表 3)。
- 深度和姿态估计也受益于合成数据,在使用少量真实数据时深度(NYU Depth V2)约有 ~10% 的提升;姿态估计相对于基线有显著提升。
- 零样本与长尾分割任务从合成数据中获益,在零样本/长尾设置中报道最高可达 ~20% 的 mIoU 提升。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。