[论文解读] Deconstructing Denoising Diffusion Models for Self-Supervised Learning
该论文将现代去噪扩散模型(DDMs)解构为潜在空间去噪自编码器(l-DAE),并显示低维潜在空间和去噪是自监督表征的关键,即使架构远比面向生成的DDMs简单。
In this study, we examine the representation learning abilities of Denoising Diffusion Models (DDM) that were originally purposed for image generation. Our philosophy is to deconstruct a DDM, gradually transforming it into a classical Denoising Autoencoder (DAE). This deconstructive procedure allows us to explore how various components of modern DDMs influence self-supervised representation learning. We observe that only a very few modern components are critical for learning good representations, while many others are nonessential. Our study ultimately arrives at an approach that is highly simplified and to a large extent resembles a classical DAE. We hope our study will rekindle interest in a family of classical methods within the realm of modern self-supervised learning.
研究动机与目标
- 激发并理解去噪扩散模型(DDMs)如何学习自监督学习的表征,而非生成。
- 系统性消融现代 DDM 的组成部分,以识别哪些部分对学习良好表征至关重要。
- 开发一个与经典去噪自编码器(DAE)高度相似的简化架构,并评估其表征质量。
- 揭示潜在空间维度和去噪与扩散过程在表征学习中的作用的新见解。
提出的方法
- 从一个用于图像生成的扩散-变换器(DiT)基线开始,并通过线性探针评估其表征质量。
- 移除类别条件化并消融分词器损失,评估对表征学习的影响。
- 探索四种分词器(卷积 VAE、块级 VAE、块级 AE、块级 PCA),研究潜在空间维度的影响。
- 逐步将扩散特定设计(噪声预测目标、输入尺度、潜在空间与图像空间操作)回复到经典 DAE 设置。
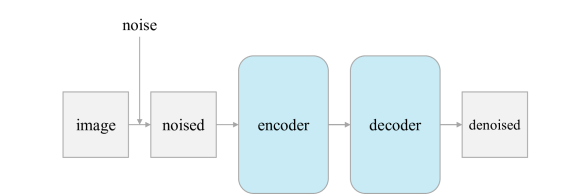
- 通过在低维潜在空间中添加噪声(通过块级 PCA)并训练一个自编码器去噪,引入潜在去噪自编码器(l-DAE),以多层噪声作为增强。
![Figure 1 : The latent Denoising Autoencoder ( l -DAE ) architecture we have ultimately reached, after a thorough exploration of deconstructing Denoising Diffusion Models (DDM) [ 23 ] , with the goal of approaching the classical Denoising Autoencoder (DAE) [ 39 ] as much as possible. Here, the clean](https://ar5iv.labs.arxiv.org/html/2401.14404/assets/x1.png)
实验结果
研究问题
- RQ1当重新定位为非生成任务时,扩散模型能否学习到用于自监督学习的强表征?
- RQ2现代 DDMs 的哪些组件对于学习表征是必需的,哪些是非必需的?
- RQ3在去噪框架中,低维潜在空间是否足以实现有效的自监督表征学习?
- RQ4去构解的 DDM 在线性评估中能否接近经典 DAEs 和 MAE 类方法的性能?
- RQ5不同分词器和噪声时间表对表征质量的影响是什么?
主要发现
| 方法 | ViT-B (86M) | ViT-L (304M) |
|---|---|---|
| MoCo v3 | 76.7 | 77.6 |
| MAE | 68.0 | 75.8 |
| l-DAE | 66.6 | 75.0 |
- DDMS 的表征能力在很大程度上来自去噪而非扩散本身。
- 删除类别条件化使线性探针准确率从 57.5% 提高到 62.1%(FID 变差,表示生成能力下降)在 DiT 基线。
- 使用感知损失训练的分词器提供语义表征;移除感知和对抗损失使其趋向于 VAE 类分词器,但并未失去全部表征能力。
- 在潜在空间使用较简单的非多层级噪声时间表将线性准确率提高到 63.4%(对比基线 59.0%),表明多层级噪声可作为增强,但并非必需。
- 使用低潜在维度(d=16-32)的块级分词器在线性探针上优于卷积 VAE 分词器,且基于 PCA 的分词器可在无需梯度训练的情况下使用。
- 向经典 DAE 靠拢时,预测干净数据而不是噪声会得到具竞争力但略低的准确率(例如该变化后为 62.4%),并且在潜在空间中进行逆 PCA 的操作可以达到图像空间的性能(63.6-63.9%)。
- 最终的潜在空间 DAE(l-DAE)采用 PCA 基分词器和多层潜在噪声,在 patch-wise PCA 基线下达到 65.1%(在 augmentation 下为 65.0%),并可随更大模型(ViT-L 在他们的比较中达到 75.0%)的扩展而提升。
- 与 MoCo v3 和 MAE 基线相比,l-DAE 与 MAE 竞争,在同等训练设置下在 ViT-B/-L 上落后 MAE 约 1-2%。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。