[论文解读] Deductive Verification of Chain-of-Thought Reasoning
本论文推出 Natural Program,一种自然语言的演绎推理格式,能够对大语言模型中每一步推理进行逐步验证,并将其与统一-多元表决(Unanimity-Plurality Voting)相结合,以提升连锁推理的严谨性、可信度与可解释性。在算术和常识数据集上的评测显示,逐步、最小前提的验证可获得更高的验证准确性,在许多情况下最终答案同样达到同等或更好,应用完整验证时偶有略微下降。
Large Language Models (LLMs) significantly benefit from Chain-of-Thought (CoT) prompting in performing various reasoning tasks. While CoT allows models to produce more comprehensive reasoning processes, its emphasis on intermediate reasoning steps can inadvertently introduce hallucinations and accumulated errors, thereby limiting models' ability to solve complex reasoning tasks. Inspired by how humans engage in careful and meticulous deductive logical reasoning processes to solve tasks, we seek to enable language models to perform explicit and rigorous deductive reasoning, and also ensure the trustworthiness of their reasoning process through self-verification. However, directly verifying the validity of an entire deductive reasoning process is challenging, even with advanced models like ChatGPT. In light of this, we propose to decompose a reasoning verification process into a series of step-by-step subprocesses, each only receiving their necessary context and premises. To facilitate this procedure, we propose Natural Program, a natural language-based deductive reasoning format. Our approach enables models to generate precise reasoning steps where subsequent steps are more rigorously grounded on prior steps. It also empowers language models to carry out reasoning self-verification in a step-by-step manner. By integrating this verification process into each deductive reasoning stage, we significantly enhance the rigor and trustfulness of generated reasoning steps. Along this process, we also improve the answer correctness on complex reasoning tasks. Code will be released at https://github.com/lz1oceani/verify_cot.
研究动机与目标
- 在 LLM 中激发与实现严格的演绎推理,以减少提出幻觉(hallucination)和错误的链式思维(CoT)
- 提出一种 Natural Program 格式,明确列出推理步骤的最小前提以提升可验证性
- 通过仅分析必要的上下文来开展逐步验证,并与投票机制结合以提高对最终答案的信任度
- 在使用 GPT-3.5-turbo 的多样推理基准上进行经验性验证,展示更强的严谨性和可解释性
提出的方法
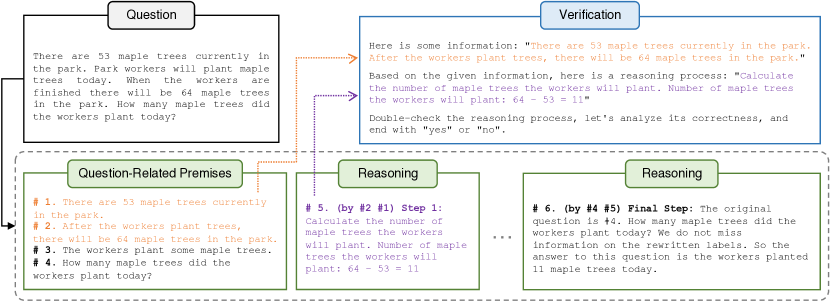
- 引入 Natural Program:一种结构化的自然语言格式,列出与问题相关的前提和逐步推理,并明确使用的前提
- 将演绎验证分解为逐步的有效性 V(s_i),使用最小所需前提 p_i,实现局部验证
- 通过在提示中包含前提、步骤描述和验证指令来进行单步有效性检查;采用一次性提示以提高可靠性
- 应用统一-多元表决(UPV):一致性阶段筛选所有步骤均有效的链,随后多元表决在经验证的链之间确定最终答案
- 评估两种情境:(i) 在未进行完整验证的 Natural Program 推理;(ii) 进行演绎验证与 UPV 的 NP 推理;在若干数据集上与 CoT 与 Faithful CoT 基线比较
- 数据集包括 GSM8K、AQuA、MATH、AddSub、Date 与 Last Letters
实验结果
研究问题
- RQ1在使用 Natural Program 格式推理时,LLM 能否验证每一步推理的演绎有效性?
- RQ2逐步、最小前提的验证是否比端到端验证更能提升推理的严谨性与可信度?
- RQ3将演绎验证与 UPV 结合对最终答案的准确性与鲁棒性有何影响?
- RQ4使用最小前提与使用全部前提对验证准确性有何影响?
主要发现
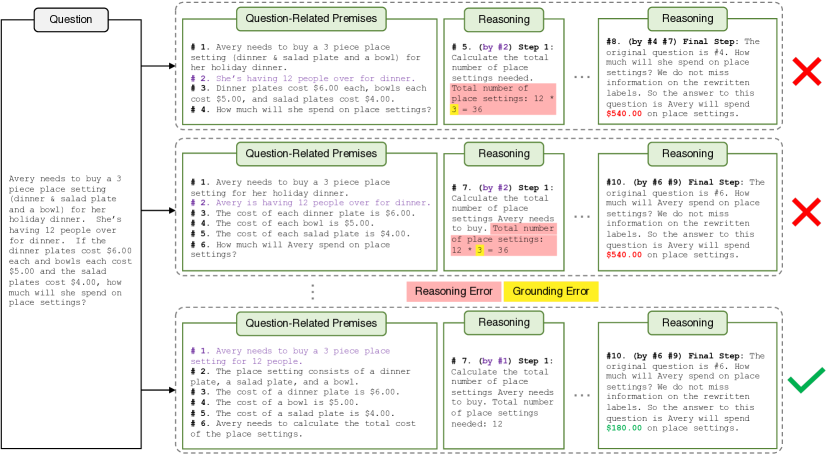
- 基于 Natural Program 的验证在大多数数据集上显著提升逐步推理验证的准确性
- 每步使用最小前提相比使用全部前提显著提升验证性能,减少了对无关上下文的干扰
- 增加单步有效性投票中的票数(k')通常会提升验证准确性,但代价是需要更多计算
- 在许多任务上以 Natural Program 格式提示模型,其最终答案的准确性与基线相比相当或更好,即使在未进行验证之前也如此
- 应用完整的演绎验证可能略微降低最终答案的准确性,因为它会过滤出产生正确答案但推理有瑕疵的链条,但这提升了推理的严谨性
- 消融研究表明前提最小化和 UPV 设置对验证准确性与最终结果均有实质性影响
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。