[论文解读] Deep Learning Based Text Classification: A Comprehensive Review
对超过150个用于文本分类的深度学习模型在情感分析、问答、自然语言推断等领域,以及40多个数据集,进行评估分析,并在16个基准上进行定量性能综述。
Deep learning based models have surpassed classical machine learning based approaches in various text classification tasks, including sentiment analysis, news categorization, question answering, and natural language inference. In this paper, we provide a comprehensive review of more than 150 deep learning based models for text classification developed in recent years, and discuss their technical contributions, similarities, and strengths. We also provide a summary of more than 40 popular datasets widely used for text classification. Finally, we provide a quantitative analysis of the performance of different deep learning models on popular benchmarks, and discuss future research directions.
研究动机与目标
- 总结应用于跨多任务的文本分类的深度学习模型全景。
- 整理并比较广泛用于文本分类的数据集。
- 对选定的深度学习模型在流行基准上的定量分析,并指出未来方向。
提出的方法
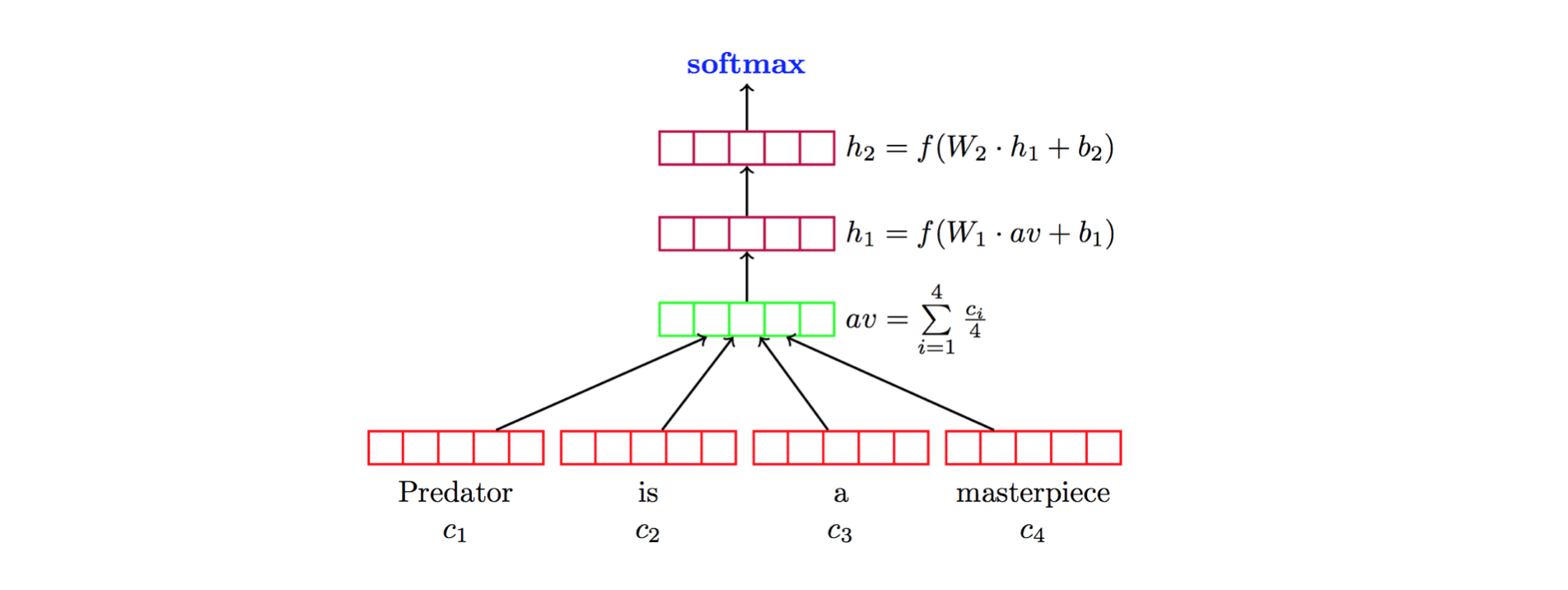
- 将深度学习模型按结构分类(RNN、CNN、Transformer、Capsule Nets、图神经网络等)以便进行结构化评述。
- 描述具有代表性的模型及其结构创新(如DAN、fastText、Word2Vec/Doc2Vec、LSTM/Tree-LSTM、CNN变体、CapsNets、注意力机制、记忆网络、GNN、Siamese网络等)。
- 总结在文本分类研究中使用的数据集(超过40个)和基准。
- 在16个标准基准上对部分DL模型进行定量比较。
实验结果
研究问题
- RQ1当前用于文本分类的主导深度学习架构有哪些,以及它们随时间的演变?
- RQ2在标准文本分类任务中,不同模型族(RNN、CNN、Transformer、CapsNets、GNNs)的表现如何?
- RQ3哪些数据集和基准在基于DL的文本分类研究中占主导地位,以及未来工作还存在哪些空白?
- RQ4注意力机制、记忆增强和基于图的方法对性能和鲁棒性有何贡献?
主要发现
- 该综述涵盖了近年来用于文本分类的超过150个深度学习模型。
- 它总结并分析了超过40个广泛使用的文本分类数据集。
- 在16个流行基准上提供了定量性能分析。
- 论文讨论了基于DL的文本分类仍然面临的挑战和未来的研究方向。
- 工作强调了从手工特征到嵌入与大规模预训练模型的发展。
- 它将模型归类为实际的家族(如RNN、CNN、Transformer、Capsule Nets、记忆网络、GNN等)。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。