[论文解读] Deep Residual Learning for Image Recognition
本文介绍了带有恒等捷径连接的残差学习,以训练更深的网络,在ImageNet上达到152层并实现最先进的结果,同时解决非常深的普通网络的退化问题。
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
研究动机与目标
- 在视觉识别中说明需要更深的网络的动机,并识别深度增加时的退化问题。
- 提出一个残差学习框架,将层重新表述为学习相对于输入的残差函数。
- 证明残差网络更易优化,随着深度增加在不同数据集(ImageNet和CIFAR-10)上受益。
- 表明极深的残差网络获得更好的准确性,并能泛化到检测/定位任务(COCO、Pascal VOC)。
- 提供实用的架构和训练策略,使极深网络的训练成为可能。
提出的方法
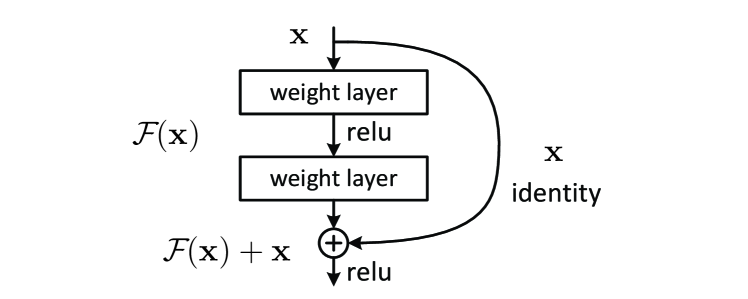
- 将目标映射 H(x) 表述为学习残差 F(x) = H(x) - x,使块计算 y = F(x) + x。
- 引入执行简单累加以传播信息的恒等捷径连接,不增加参数或计算成本。
- 探索网络变体,包括普通网络和残差网络,研究深度从18到152层,并使用非瓶颈和瓶颈残差块。
- 在普通网络和残差块中使用3x3卷积核,捷径连接为恒等或在维度改变时使用投影。
- 为更深模型采用瓶颈设计(1x1、3x3、1x1),在增加深度的同时保持计算成本在合理范围内。
- 在ImageNet、CIFAR-10和COCO/Pascal VOC基准上使用SGD、批量归一化和标准图像增强进行训练;评估Top-1和Top-5错误,以及检测中的mAP。
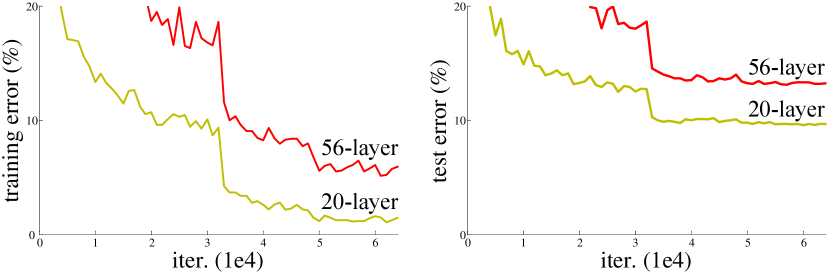
实验结果
研究问题
- RQ1非常深的普通网络的退化问题是否会阻碍优化,残差学习是否能缓解?
- RQ2相比较浅的等效网络,显著更深的残差网络(最多152层)在ImageNet和CIFAR-10上是否能提升准确性?
- RQ3身份捷径与投影捷径在训练容易度和性能方面有何区别?
- RQ4极深的残差网络是否能泛化到对象检测/分割任务(COCO、Pascal VOC)而不仅仅是图像分类?
- RQ5平衡深度、计算和精度的实际架构变体(普通 vs 残差,瓶颈 vs 非瓶颈)是什么?
主要发现
- 深度普通网络存在退化:更深的网络可能具有更高的训练误差和更差的验证性能。
- 带跳跃连接的残差网络解决了退化问题,深度增加时能够获得更高的准确性(例如 ResNet-34 相对于 ResNet-18)。
- 在ImageNet上, ResNet-50/101/152 的Top-1误差分别为22.85%、21.75%、21.43%(单模型结果),Top-5误差分别为6.71%、6.05%、5.71%。
- 对ImageNet测试集的一个残差网络集合达到3.57%的Top-5误差,赢得ILSVR C 2015分类比赛第一名。
- 在CIFAR-10上,残差网络带来强劲提升,ResNet-110达到6.43%(单次运行中最好记录),更深的变体进一步提升。
- 在COCO上,用ResNet-101替换VGG-16在检测任务中取得显著提升(mAP提升),展示对其他视觉任务的强泛化能力。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。