[论文解读] DeepSRGM -- Sequence Classification and Ranking in Indian Classical Music with Deep Learning
DeepSRGM 使用带注意力的 LSTM 进行 Raga 识别作为序列分类,并引入基于 Raga 的内容检索的序列排序,在 Comp Music Carnatic 数据集上达到最先进的结果。
A vital aspect of Indian Classical Music (ICM) is Raga, which serves as a melodic framework for compositions and improvisations alike. Raga Recognition is an important music information retrieval task in ICM as it can aid numerous downstream applications ranging from music recommendations to organizing huge music collections. In this work, we propose a deep learning based approach to Raga recognition. Our approach employs efficient pre possessing and learns temporal sequences in music data using Long Short Term Memory based Recurrent Neural Networks (LSTM-RNN). We train and test the network on smaller sequences sampled from the original audio while the final inference is performed on the audio as a whole. Our method achieves an accuracy of 88.1% and 97 % during inference on the Comp Music Carnatic dataset and its 10 Raga subset respectively making it the state-of-the-art for the Raga recognition task. Our approach also enables sequence ranking which aids us in retrieving melodic patterns from a given music data base that are closely related to the presented query sequence.
研究动机与目标
- 使用 LSTM-RNN+注意力,将 Raga 识别重新表述为序列分类问题,以支持组织和推荐大型音乐集合。
- 使用带注意力的 LSTM-RNN 将 Raga 识别重新表述为序列分类问题。
- 引入序列排序,以检索与查询序列密切相关的序列,用于基于内容的检索。
提出的方法
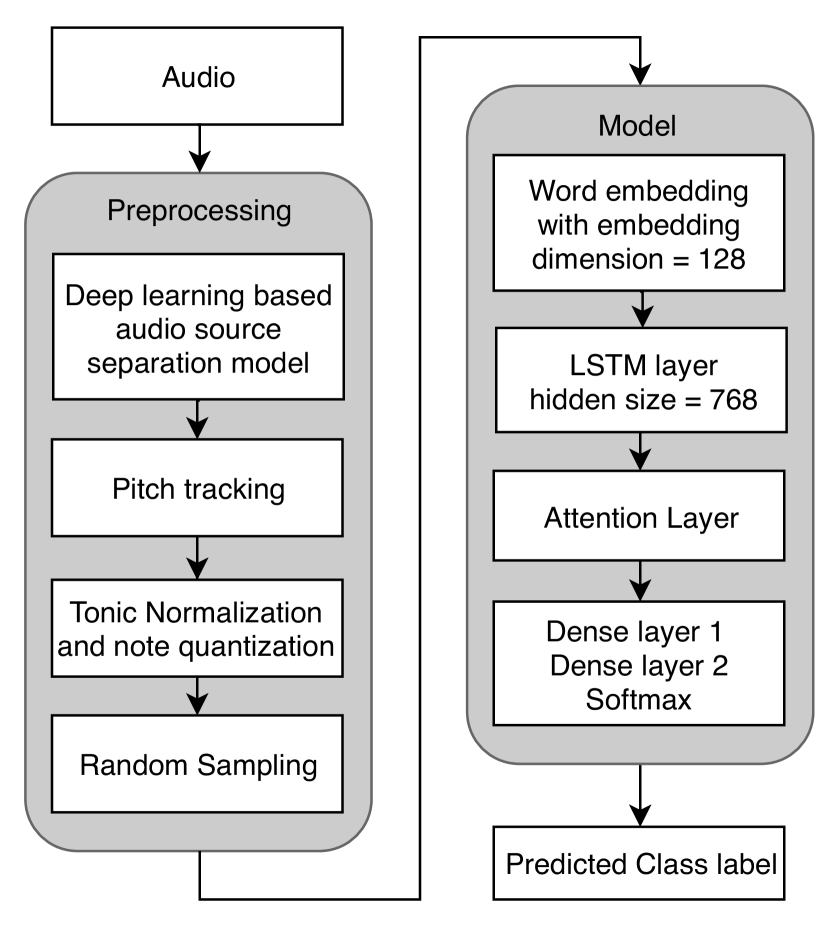
- 通过人声源分离和音高跟踪对音频进行预处理。
- 使用以主音为基点,在分音(cents)单位中对音调进行规范化。
- 训练一个具有 768 个隐藏单元和 128 维音符嵌入的 LSTM-RNN,随后加上注意力层和全连接层。
- 使用分类交叉熵损失和 Adam 优化器,并进行分布式异步 SGD 训练。
实验结果
研究问题
- RQ1是否可以将 Raga 识别有效建模为使用带注意力的 LSTM 对经量化音高序列进行序列分类的问题?
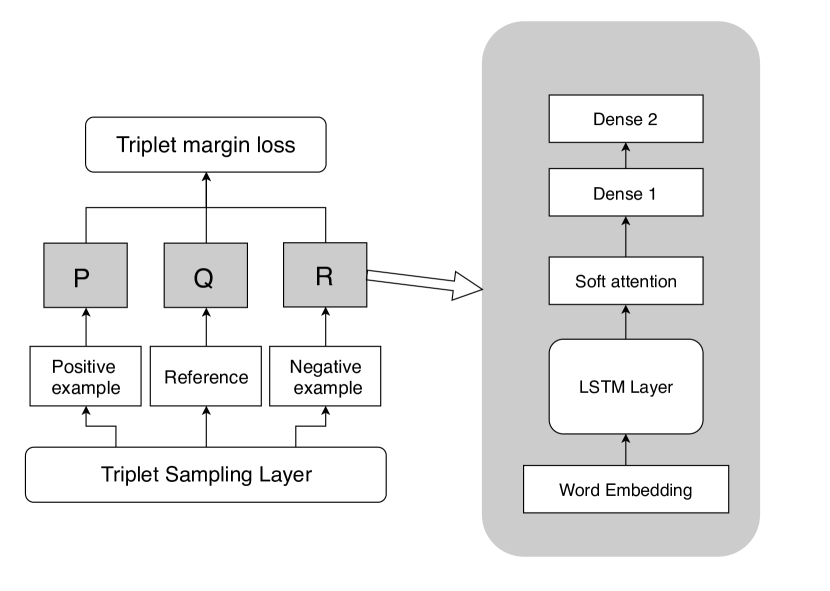
- RQ2使用三元组损失进行微调的模型是否能实现对基于 Raga 的检索的可靠序列排序?
- RQ3子序列长度和采样如何影响 CMD 上的识别和排序性能?
- RQ4使用 SRGM1 及其集成,在 CMD-10 与 CMD-40 上的最先进性能水平是多少?
- RQ5模型是否能在大型 ICM 数据集内实现基于内容的检索的泛化?
主要发现
| 方法 | CMD-10 Ragas | CMD-40 Ragas |
|---|---|---|
| SRGM1 | 95.6% | 84.6% |
| SRGM1 Ensemble | 97.1% | 88.1% |
- SRGM1 在 CMD-10 Ragascales 上达到 95.6% 的准确率,在 CMD-40 Ragascales 上达到 84.6%。
- SRGM1 Ensemble 提高到 97.1%(CMD-10)和 88.1%(CMD-40)。
- SRGM2(序列排序)获得前 30 名准确率 81.83%,前 10 名准确率 81.68%。
- 该模型在 CMD 及 CMD-10 子集上优于先前的 TDMS、VSM 和基于 PCD 的方法。
- 更长的子序列(例如 6000 步)收敛更快,且比较短子序列具有更好的稳定性。
- 使用随机子序列和基于注意力的 LSTM 训练可提升 Raga 识别性能。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。