[论文解读] Diff-Instruct: A Universal Approach for Transferring Knowledge From Pre-trained Diffusion Models
Diff-Instruct 通过在扩散过程上最小化积分 KL 发散,将来自预训练扩散模型的知识传递给任意隐式生成模型,数据无关,能够实现扩散蒸馏并提升 GAN 生成器,在基准数据集上取得强劲结果。
Due to the ease of training, ability to scale, and high sample quality, diffusion models (DMs) have become the preferred option for generative modeling, with numerous pre-trained models available for a wide variety of datasets. Containing intricate information about data distributions, pre-trained DMs are valuable assets for downstream applications. In this work, we consider learning from pre-trained DMs and transferring their knowledge to other generative models in a data-free fashion. Specifically, we propose a general framework called Diff-Instruct to instruct the training of arbitrary generative models as long as the generated samples are differentiable with respect to the model parameters. Our proposed Diff-Instruct is built on a rigorous mathematical foundation where the instruction process directly corresponds to minimizing a novel divergence we call Integral Kullback-Leibler (IKL) divergence. IKL is tailored for DMs by calculating the integral of the KL divergence along a diffusion process, which we show to be more robust in comparing distributions with misaligned supports. We also reveal non-trivial connections of our method to existing works such as DreamFusion, and generative adversarial training. To demonstrate the effectiveness and universality of Diff-Instruct, we consider two scenarios: distilling pre-trained diffusion models and refining existing GAN models. The experiments on distilling pre-trained diffusion models show that Diff-Instruct results in state-of-the-art single-step diffusion-based models. The experiments on refining GAN models show that the Diff-Instruct can consistently improve the pre-trained generators of GAN models across various settings.
研究动机与目标
- 在没有真实训练数据的情况下,激发从预训练扩散模型(DMs)学习。
- 开发一个通用框架,利用 DM 知识来指导隐式生成器。
- 引入针对扩散过程的积分 KL(IKL)发散。
- 展示 Diff-Instruct 能将 DM 知识蒸馏到单步生成器并改善 GAN 生成器。
- 强调与 DreamFusion 和对抗训练的联系。
提出的方法
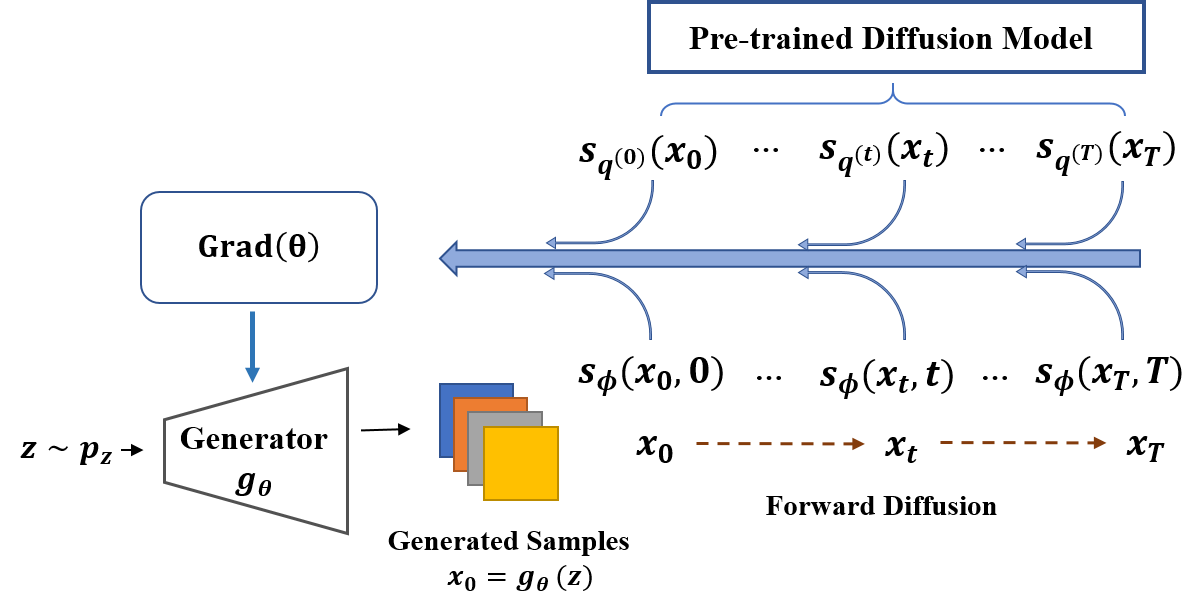
- 通过在相同正向扩散过程中对隐式生成器输出和预训练 DM 同步扩散,定义一个通用的指令目标。
- Introduce Integral KL (IKL) divergence as the objective, integrating KL divergences across diffusion time with a weighting function.
- 将 IKL 作为目标,跨扩散时间对 KL 发散进行积分并引入权重函数。
- 通过 IKL 导出生成器梯度,该梯度仅依赖于扩散过程的边际分数函数,实现数据无监督。
- 提出交替优化:/a)为生成样本训练边际分数网络,/b)使用 IKL 梯度更新生成器参数(方程3.2)。
- 证明 SDS 在生成器输出 Dirac δ 时是 Diff-Instruct 的一个特例(推论3.4)。
- 将 Diff-Instruct 与 GAN 训练联系起来,注意 IKL 在零时间权重下简化为 KL 最小化(推论3.5)。
实验结果
研究问题
- RQ1可以在没有真实数据的情况下,将来自预训练扩散模型的知识传递给任意隐式生成模型吗?
- RQ2如何利用前向扩散过程通过 IKL 发散对学生生成器进行监督?
- RQ3Diff-Instruct、DreamFusion 与传统 GAN 训练之间的关系是什么?
主要发现
- Diff-Instruct 在基于单步扩散的模型中,在 ImageNet64×64 的扩散蒸馏任务上达到最先进的性能。
- 在蒸馏到 GAN 风格生成器时,Diff-Instruct 能持续提升预训练的 GAN 生成器(如 CIFAR-10 上的 StyleGAN-2)。
- 在 CIFAR-10 无条件生成上,Diff-Instruct 获得具有竞争力的 FID;在有条件生成时,甚至可以优于一些扩散基线。
- 在 CIFAR-10 与 ImageNet64 的单步扩散蒸馏中,Diff-Instruct 提供快速收敛并显著提升采样速度(例如 1 步生成器实现强烈的 FID/IS)。
- 该方法仍然数据无关:它使用预训练 DM 的分数函数来更新学生模型,而不需要真实数据。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。