[论文解读] Diffusion-RWKV: Scaling RWKV-Like Architectures for Diffusion Models
Diffusion-RWKV 将 RWKV 背骨适配用于基于扩散的图像合成,在与 Transformer 基于扩散模型相比时,以线性时间复杂度和更低的 FLOPs 实现具有竞争力的图像质量。
Transformers have catalyzed advancements in computer vision and natural language processing (NLP) fields. However, substantial computational complexity poses limitations for their application in long-context tasks, such as high-resolution image generation. This paper introduces a series of architectures adapted from the RWKV model used in the NLP, with requisite modifications tailored for diffusion model applied to image generation tasks, referred to as Diffusion-RWKV. Similar to the diffusion with Transformers, our model is designed to efficiently handle patchnified inputs in a sequence with extra conditions, while also scaling up effectively, accommodating both large-scale parameters and extensive datasets. Its distinctive advantage manifests in its reduced spatial aggregation complexity, rendering it exceptionally adept at processing high-resolution images, thereby eliminating the necessity for windowing or group cached operations. Experimental results on both condition and unconditional image generation tasks demonstrate that Diffison-RWKV achieves performance on par with or surpasses existing CNN or Transformer-based diffusion models in FID and IS metrics while significantly reducing total computation FLOP usage.
研究动机与目标
- Explore adapting RWKV architectures for diffusion-based image generation tasks.
- Investigate conditioning, skip connections, and model scaling to ensure stability and scalability.
- Provide empirical baselines across pixel and latent space representations on multiple datasets.
- Compare performance with CNN/Transformer diffusion baselines in terms of quality and efficiency.
提出的方法
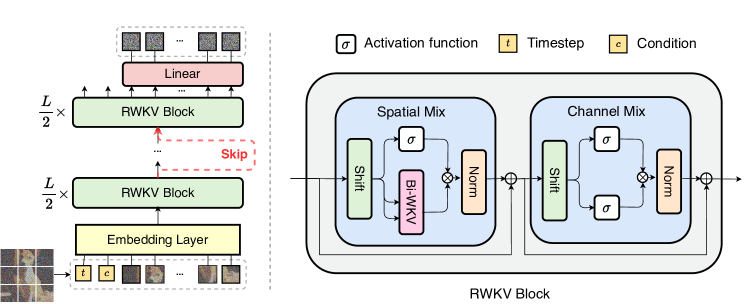
- Use Bi-RWKV as the backbone to process patchified image tokens in a bidirectional, linear-complexity fashion.
- Replace standard self-attention with a bidirectional RWKV-based mechanism including quad-directional spatial shifts and global linear attention.
- Incorporate conditioning via in-context tokens, adaLN, or adaLN-Zero for timestep and class information.
- Employ patchify-and-embed image tokens with positional embeddings to form a token sequence.
- Apply a skip-connection framework that concatenates shallow and deep branch states before a linear projection.
- Decode final Bi-RWKV outputs through a linear decoder to predict noise and diagonal covariance for DDPM-based sampling.
实验结果
研究问题
- RQ1How does a diffusion model built on RWKV-like backbones perform on high-resolution image generation tasks compared to Transformer-based diffusion models?
- RQ2What architectural choices (patch size, skip connections, conditioning) most effectively balance quality, speed, and scalability?
- RQ3Can Diffusion-RWKV achieve competitive FID/IS with lower FLOPs and memory usage at various resolutions?
- RQ4How does model scaling (depth/width) influence performance and efficiency across datasets like CIFAR-10, CelebA, and ImageNet?
主要发现
| 模型 | #Params | FID ↓ |
|---|---|---|
| DRWKV-S/2 | 39M | 3.03 |
| DRWKV-H/2 | 2.95 | 4.95 |
- Diffusion-RWKV achieves comparable or better FID results than CNN/Transformer diffusion models under similar training settings.
- Smaller patch sizes and long-skip concatenation improve generation quality and training efficiency.
- AdaLN-Zero conditioning provides superior FID performance and efficiency versus in-context conditioning.
- Larger Bi-RWKV models yield better FID with increasing FLOPs, demonstrating scalable improvements akin to DiT baselines.
- On ImageNet 256x256, DRWKV-H/2 attains competitive FID with lower total FLOPs (relative to some state-of-the-art models).
- At 512x512, DRWKV-H/2 remains competitive, approaching top-tier methods while reducing computational burden.

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。