[论文解读] DiffusionDet: Diffusion Model for Object Detection
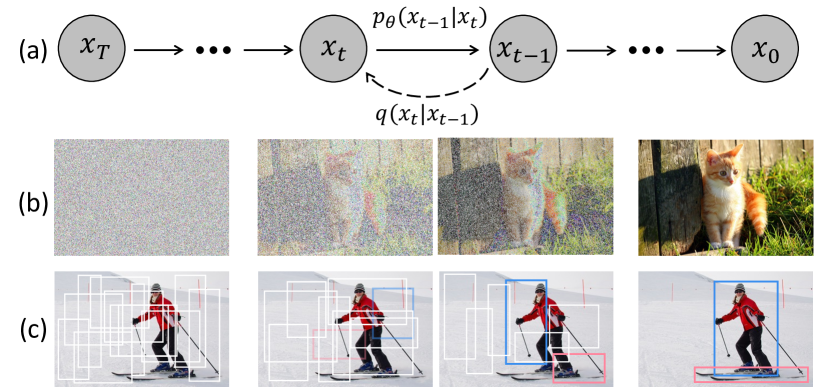
DiffusionDet 将对象检测视为一个去噪扩散过程,将随机框精炼为对象框,从而支持动态数量的候选框并进行迭代评估,性能具有竞争力。
We propose DiffusionDet, a new framework that formulates object detection as a denoising diffusion process from noisy boxes to object boxes. During the training stage, object boxes diffuse from ground-truth boxes to random distribution, and the model learns to reverse this noising process. In inference, the model refines a set of randomly generated boxes to the output results in a progressive way. Our work possesses an appealing property of flexibility, which enables the dynamic number of boxes and iterative evaluation. The extensive experiments on the standard benchmarks show that DiffusionDet achieves favorable performance compared to previous well-established detectors. For example, DiffusionDet achieves 5.3 AP and 4.8 AP gains when evaluated with more boxes and iteration steps, under a zero-shot transfer setting from COCO to CrowdHuman. Our code is available at https://github.com/ShoufaChen/DiffusionDet.
研究动机与目标
- 通过对边界框空间应用扩散,激发出一个更简单、可学习而不需要查询的对象检测器。
- 解耦训练与推理,以实现动态数量的候选框和迭代细化。
- 在 COCO、CrowdHuman 和 LVIS 基准上展示具有竞争力的性能,包括零-shot 转移场景。
提出的方法
- 在训练期间将检测建模为从真值框到嘈杂框的扩散过程。
- 使用图像编码器和一个六阶段检测头,在有噪声输入的条件下预测框。
- 对真值框进行填充,并应用带余弦调度的高斯噪声来创建训练目标。
- 推理阶段,从随机框开始,利用带时间步条件的学习检测头进行迭代去噪。
- 通过在多个步骤中重复使用检测头,并应用框更新与基于 DDIM 的更新,启用迭代评估。
- 允许在不重新训练的情况下,使用任意数量的框和步骤进行评估的灵活性。
实验结果
研究问题
- RQ1目标检测是否可以有效地被表述为对边界框的去噪扩散过程?
- RQ2基于扩散的检测器是否在不重新训练的情况下支持动态数量的候选框和迭代细化?
- RQ3与现有检测器相比,DiffusionDet 在标准及零-shot 转移基准(COCO、CrowdHuman、LVIS)上的表现如何?
主要发现
| 模型 | AP | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|
| DiffusionDet (1 @ 300) | 45.8 | 64.1 | 50.4 | 27.6 | 48.7 | 62.2 |
| DiffusionDet (4 @ 300) | 42.0 | 55.8 | 44.9 | 34.8 | 40.9 | 46.4 |
| DiffusionDet (1 @ 500) | 46.3 | 64.8 | 50.7 | 28.6 | 49.0 | 62.1 |
| DiffusionDet (4 @ 500) | 46.8 | 65.3 | 51.8 | 29.6 | 49.3 | 62.2 |
| Swin-Base Backbone DiffusionDet (4 @ 300) | 42.0 | 55.8 | 44.9 | 34.8 | 40.9 | 46.4 |
- DiffusionDet 在 COCO 上取得具有竞争力的结果,例如在 1×300 设置下的 45.8 AP,并在增加框数或步骤时有提升(如在 COCO 上 4×500 时达到 46.8 AP)。
- 在从 COCO 到 CrowdHuman 的零-shot 转移中,将评估框从 300 增加到 2000、迭代从 1 增加到 4 时,AP 分别提高了 5.3 和 4.8。
- 使用 Swin-Base 骨干网络的 DiffusionDet 在 COCO 验证集 1@300 时达到 52.5 AP,超越若干基线,并在增加步骤/骨干网络后进一步提升。
- LVIS 结果显示,更多评估步骤可带来收益,例如 4@300 或 4@500 骨干网络的 AP 高于 1@300,尤其在较大骨干网络时。
- 该模型支持动态数量的框和迭代评估且无需重新训练,使其与固定查询检测器区分开来。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。