[论文解读] Direct speech-to-speech translation with a sequence-to-sequence model
本文提出 Translatotron,一种端到端的序列到序列模型,可直接将一种语言的语音翻译为另一种语言的语音,无需中间文本表示。训练过程中通过语音转文本转录头进行多任务学习以稳定训练,同时实现语音迁移以保留源说话人的语音特征;尽管性能仍落后于级联系统,但证明了端到端训练下直接语音到语音翻译与说话人身份保留的可行性。
We present an attention-based sequence-to-sequence neural network which can directly translate speech from one language into speech in another language, without relying on an intermediate text representation. The network is trained end-to-end, learning to map speech spectrograms into target spectrograms in another language, corresponding to the translated content (in a different canonical voice). We further demonstrate the ability to synthesize translated speech using the voice of the source speaker. We conduct experiments on two Spanish-to-English speech translation datasets, and find that the proposed model slightly underperforms a baseline cascade of a direct speech-to-text translation model and a text-to-speech synthesis model, demonstrating the feasibility of the approach on this very challenging task.
研究动机与目标
- 开发一种直接的端到端语音到语音翻译系统,绕过中间的文本表示。
- 探究在无中间文本表示的直接语音到语音翻译中,使用语音转文本转录头的多任务训练是否能稳定训练过程,同时不损害端到端推理能力。
- 实现语音迁移,确保翻译输出语音中保留源说话人的声音特征。
- 在真实世界的西班牙语到英语语音翻译数据集上评估模型性能,并与级联基线系统进行比较。
- 探索在统一的端到端框架中学习跨语言语调与说话人身份迁移的可行性。
提出的方法
- 模型使用8层双向LSTM编码器堆叠结构,结合注意力机制,处理输入语音的频谱图和说话人嵌入。
- 采用双流解码器:一个用于生成目标频谱图,另一个用于音素预测,从而实现与辅助转录任务的多任务学习。
- 说话人编码器从参考语句中提取说话人嵌入,训练期间用于控制语音迁移过程。
- 模型通过合成目标数据与真实语音数据的组合进行端到端训练,损失函数包括翻译损失、音素识别损失和语音迁移损失。
- 通过同时对源语音和目标说话人嵌入进行条件控制,实现语音迁移,从而在源说话人语音风格下生成合成语音。
- 声码器将预测的频谱图转换为波形输出,用于评估。
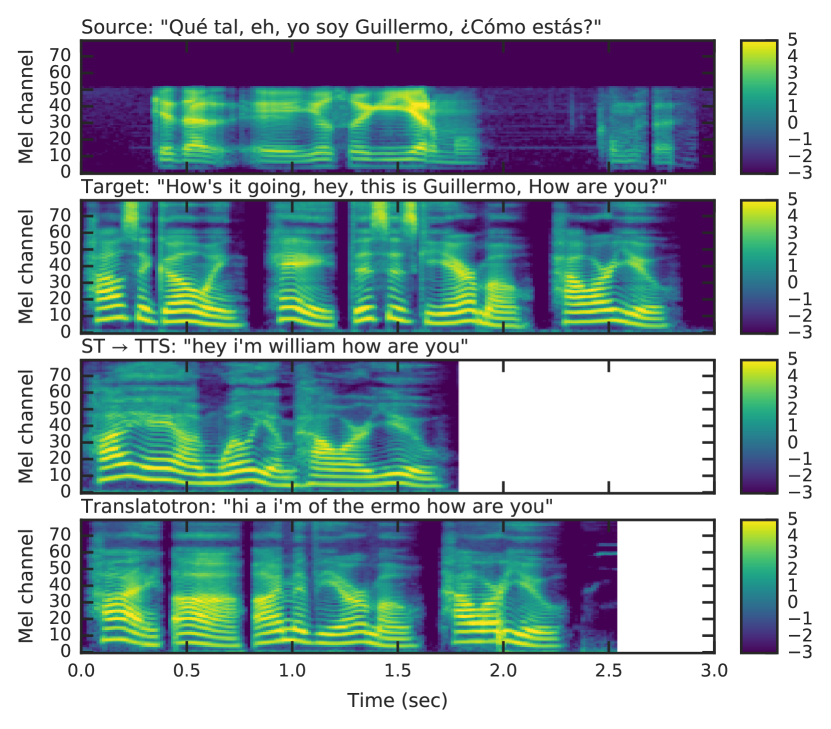
实验结果
研究问题
- RQ1端到端的序列到序列模型能否在不依赖中间文本表示的情况下实现直接语音到语音翻译?
- RQ2使用辅助语音转文本转录头的多任务训练在稳定直接语音到语音翻译训练方面有多有效?
- RQ3该模型在多大程度上能保留翻译输出语音中的源说话人声音特征?
- RQ4与语音转文本翻译加文本转语音合成的级联系统相比,直接语音到语音翻译模型的性能如何?
- RQ5在训练直接语音到语音翻译模型时,主要挑战是什么,特别是对齐问题和数据稀缺问题?
主要发现
- 当以源说话人语音为条件时,直接语音到语音翻译模型的BLEU得分为33.6,而使用真实目标说话人嵌入时为36.2。
- 尽管有辅助转录任务的监督,模型的翻译质量仍略低于级联的ST+TTS基线系统,表明直接训练仍具挑战性。
- 当以源说话人为条件时,语音迁移性能显著下降(MOS相似度:1.85),而使用真实目标说话人时为3.30,表明跨语言说话人嵌入泛化能力差。
- 以随机目标语句为条件时,BLEU得分(35.4)和MOS得分(3.08)与以源说话人为条件时相近,表明说话人嵌入中未出现显著的内容泄露。
- 模型成功保留了同源词和专有名词(例如,'Guillermo' 被保留为 'Guillermo' 而非翻译为 'William'),表明其对直接音素保留存在偏向。
- 结果表明,通过辅助转录任务的端到端训练,即使在平行语音数据有限的情况下,也能实现直接语音到语音翻译的稳定学习。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。