[论文解读] Divergence-Augmented Policy Optimization
引入发散增强(divergence augmentation)到策略优化,通过在强化学习目标中加入基于发散的正则化项;从状态-动作分布之间的Bregman发散推导而来,并在数据稀缺的离策略重用下在Atari上展示了性能提升。
In deep reinforcement learning, policy optimization methods need to deal with issues such as function approximation and the reuse of off-policy data. Standard policy gradient methods do not handle off-policy data well, leading to premature convergence and instability. This paper introduces a method to stabilize policy optimization when off-policy data are reused. The idea is to include a Bregman divergence between the behavior policy that generates the data and the current policy to ensure small and safe policy updates with off-policy data. The Bregman divergence is calculated between the state distributions of two policies, instead of only on the action probabilities, leading to a divergence augmentation formulation. Empirical experiments on Atari games show that in the data-scarce scenario where the reuse of off-policy data becomes necessary, our method can achieve better performance than other state-of-the-art deep reinforcement learning algorithms.
研究动机与目标
- 在重用离策略数据时,促进策略优化的稳定性。
- 引入基于状态-动作分布发散的正则化作为发散增强。
- 从Bregman发散和镜像下降原则推导该方法。
- 提出一个实用的基于梯度的发散增强更新优化方案。
提出的方法
- 使用当前与先前的状态-动作分布之间的Bregman发散来定义发散增强。
- 将发散增强与基于KL的更新以及基于镜像下降的优化联系起来。
- 推导将发散增强纳入策略损失的梯度表达式(包括 \u001abla_theta L_pi 和 \u001abla_theta D_F 项)。
- 通过 V-trace 为离策略数据估计 Q 值和发散项。
- 实现一个基于梯度的更新:theta <- theta - alpha_t (grad_theta L_pi + b grad_theta L_v)。
- 提供一个实用算法(DAPO),交替进行轨迹收集、离策略采样和梯度更新。
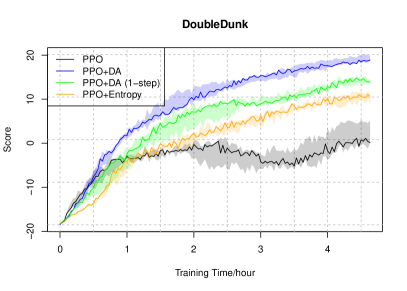
实验结果
研究问题
- RQ1当重用离策略数据时,发散增强是否能稳定策略优化?
- RQ2如何将状态-动作分布之间的Bregman发散整合到策略梯度更新中?
- RQ3在数据稀缺的强化学习设置中,发散增强对性能的影响是什么?
- RQ4DAPO 与现有方法如 PPO、TRPO、MPO、MARWIL 的关系与区别是什么?
主要发现
- DAPO 在数据稀缺情景下可以提升相较于标准PPO的性能。
- 发散增强相当于在状态-动作空间上施加一个Bregman发散约束。
- 该发散项的梯度可以用类似策略梯度方法的Q-运算符来估计。
- 如文中提及的Atari实验所示,使用发散增强在重用离策略数据时有帮助。
- 该方法与在线镜像下降相关,并将KL为基础的策略更新推广。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。