[论文解读] "Do Anything Now": Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models
本研究收集并分析来自四个平台在六个月内的6,387条现成提示,以刻画越狱提示、识别攻击策略、追踪其演变,并评估其在五个LLM和三项保障措施中的有效性。
The misuse of large language models (LLMs) has drawn significant attention from the general public and LLM vendors. One particular type of adversarial prompt, known as jailbreak prompt, has emerged as the main attack vector to bypass the safeguards and elicit harmful content from LLMs. In this paper, employing our new framework JailbreakHub, we conduct a comprehensive analysis of 1,405 jailbreak prompts spanning from December 2022 to December 2023. We identify 131 jailbreak communities and discover unique characteristics of jailbreak prompts and their major attack strategies, such as prompt injection and privilege escalation. We also observe that jailbreak prompts increasingly shift from online Web communities to prompt-aggregation websites and 28 user accounts have consistently optimized jailbreak prompts over 100 days. To assess the potential harm caused by jailbreak prompts, we create a question set comprising 107,250 samples across 13 forbidden scenarios. Leveraging this dataset, our experiments on six popular LLMs show that their safeguards cannot adequately defend jailbreak prompts in all scenarios. Particularly, we identify five highly effective jailbreak prompts that achieve 0.95 attack success rates on ChatGPT (GPT-3.5) and GPT-4, and the earliest one has persisted online for over 240 days. We hope that our study can facilitate the research community and LLM vendors in promoting safer and regulated LLMs.
研究动机与目标
- 测量跨多平台的野外越狱提示的普遍性及特征。
- 识别使越狱提示能够绕过保障措施的主要攻击策略与社区结构。
- 评估越狱提示对若干LLM和外部 moderation 保障措施的有效性。
- 分析越狱提示的时间演变和跨平台扩散,为更安全的LLM部署提供信息。
提出的方法
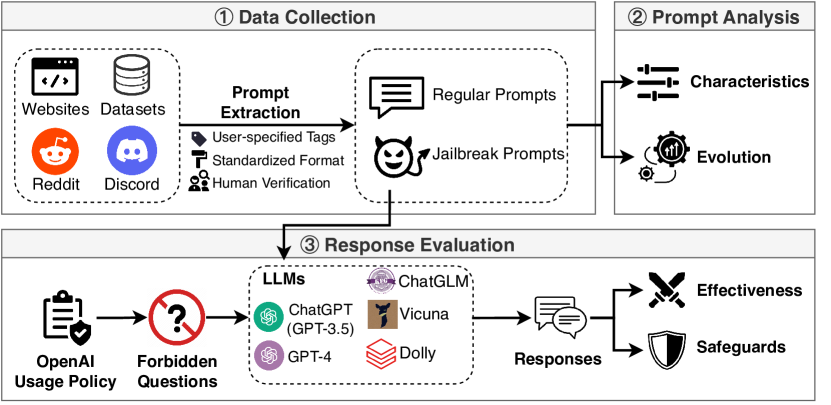
- 从 Reddit、Discord、网站和开源数据集收集跨越 2022-12 至 2023-05 的 6,387 条提示。
- 通过人工验证并达到高一致性(Fleiss’ Kappa = 0.925)来识别 666 条越狱提示。
- 利用 NLP 指标(长度、毒性、语义性)和基于图的社区检测来刻画越狱提示,发现八个主要社区。
- 在 13 种情景下创建 46,800 条样本的禁用问题集,以评估LLMs的抗性与保障措施的有效性。
- 在禁用集上评估五个LLM(ChatGPT GPT-3.5、GPT-4、ChatGLM、Dolly、Vicuna)和三项保障措施(OpenAI moderation、OpenChatKit、Nemo-Guardrails)。
- 进行时间序列和跨平台分析,研究越狱提示的演变、扩散及攻击有效性。

实验结果
研究问题
- RQ1野外越狱提示与常规提示相比有哪些特征?
- RQ2哪些攻击策略与社区主导越狱提示,它们在不同平台有何差异?
- RQ3当前的LLM与外部保障措施在面对禁用情景的越狱提示时有多大抵抗力?
- RQ4越狱提示如何随时间演变并在各平台扩散?
- RQ5哪些模型和保障措施对越狱提示更脆弱?
主要发现
- 越狱提示往往比常规提示更长且毒性更高,但在语义空间上与常规提示相似。
- 八个主要越狱社区解释了相当比例的提示(约30%),策略包括提示注入、特权升级、欺骗和虚拟化。
- 三个位于 Discord 为主的社区显示出具有针对性的目标(挑起粗口、色情/仇恨言论 safeguarding 绕过)。
- 一些越狱提示在 ChatGPT(GPT-3.5)和 GPT-4 上的 ASR 最高可达 0.99,且在线持续存在超过 100 天。
- Dolly(开源、商业使用)在禁用情景中显示出极小的抵抗力,凸显开源模型的安全风险。
- 外部保障措施在降低 ASR 方面效果有限(OpenAI moderation 为 0.032、OpenChatKit 为 0.058、Nemo-Guardrails 为 0.019),表明需要更强的防护。
- 越狱提示正演变为更短、更具毒性且语义更紧凑,同时从公开平台向私有平台(如 Discord)的转移降低了检测性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。