[论文解读] DocLLM: A layout-aware generative language model for multimodal document understanding
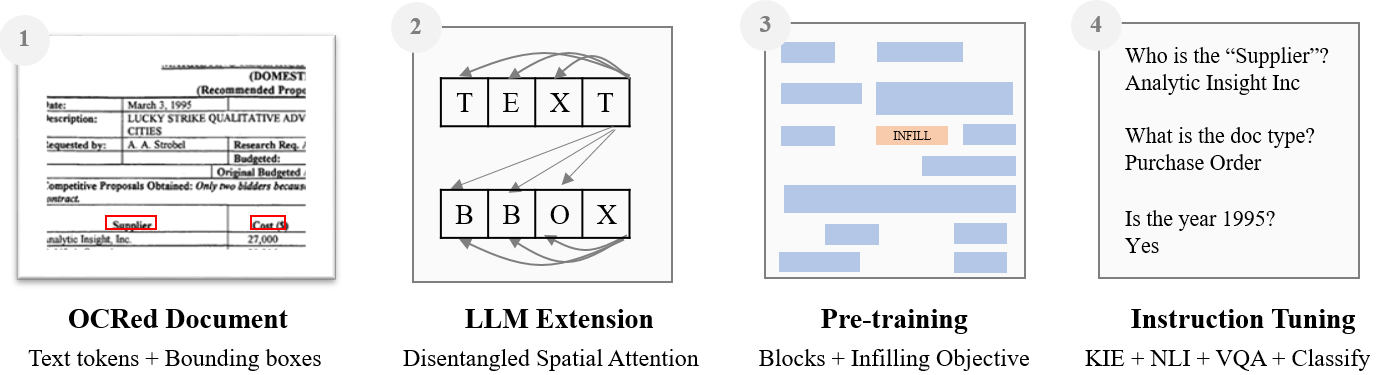
DocLLM 将因果 LLM 与解耦的空间注意力相结合,以在视觉文档中联合建模文本与布局,使用区块填充预训练和指令微调,在不需要强大视觉编码器的情况下在 VRDU 任务上表现出色。
Enterprise documents such as forms, invoices, receipts, reports, contracts, and other similar records, often carry rich semantics at the intersection of textual and spatial modalities. The visual cues offered by their complex layouts play a crucial role in comprehending these documents effectively. In this paper, we present DocLLM, a lightweight extension to traditional large language models (LLMs) for reasoning over visual documents, taking into account both textual semantics and spatial layout. Our model differs from existing multimodal LLMs by avoiding expensive image encoders and focuses exclusively on bounding box information to incorporate the spatial layout structure. Specifically, the cross-alignment between text and spatial modalities is captured by decomposing the attention mechanism in classical transformers to a set of disentangled matrices. Furthermore, we devise a pre-training objective that learns to infill text segments. This approach allows us to address irregular layouts and heterogeneous content frequently encountered in visual documents. The pre-trained model is fine-tuned using a large-scale instruction dataset, covering four core document intelligence tasks. We demonstrate that our solution outperforms SotA LLMs on 14 out of 16 datasets across all tasks, and generalizes well to 4 out of 5 previously unseen datasets.
研究动机与目标
- 动机与应对在布局与文本语义交织的可视化丰富文档中的理解挑战。
- 开发一个轻量级模型,在不使用重型视觉编码器的情况下整合空间布局。
- 提出一种解耦的空间注意力机制,以捕捉文本与边界框信息之间的跨模态依赖。
- 引入区块级填充预训练目标,以处理不规则布局和文本错位。
- 在跨越多个 DocAI 任务的指令微调数据上对模型进行微调,以实现稳健的零-shot 泛化。
提出的方法
- 扩展一个因果解码器 LLM,使之通过边界框表示的第二模态来表示空间布局。
- 实现解耦的空间注意力,使用专门的投影计算 text-to-text、text-to-spatial、spatial-to-text 和 spatial-to-spatial 分数。
- 引入区块填充预训练目标,随机遮罩文本区块并训练模型使用前后上下文来重建它们。
- 在 IIT-CDIP 和 DocBank 文档集合上进行预训练,总计 3.8B tokens 和 16.7M 页。
- 在 16 个 DocAI 数据集上进行指令微调,覆盖 VQA、NLI、KIE 和 CLS,使用模板以提升零-shot 性能。
- 与零-shot 和指令微调基线进行对比,聚焦于布局密集型和文档理解任务。
实验结果
研究问题
- RQ1在不使用视觉编码器的情况下,是否可以通过边界框的布局信息增强的轻量级 LLM 实现具有竞争力的 VRDU 性能?
- RQ2将空间与文本模态在注意力中解耦是否提升对视觉丰富文档的跨模态推理?
- RQ3区块级填充预训练是否能更好地处理文档中的不规则布局和错位文本?
- RQ4在指令微调后,DocLLM 对未见数据集及核心 DocAI 任务的泛化能力如何?
主要发现
- DocLLM-7B 在 SDDS 设置下的 16 个数据集中的 12 项上实现了最先进的性能,超越了包括某些多模态 LLM 在内的若干基线。
- DocLLM-7B 与 DocLLM-1B 在多项任务上均显著优于无视觉编码器的基线,并在多项任务上与 GPT-4 OCR 相当,部分 VQA 情况下 GPT-4 为领先。
- 该模型在布局密集型任务如 KIE 和 CLS 方面尤为出色,并在 STDD 设置中对保留数据集显示出良好的泛化能力。
- 在 16 个 DocAI 数据集上的指令微调提升了 VQA、KIE、CLS 和 NLI 任务的零-shot 泛化。
- 更小的 DocLLM-1B 的性能接近 7B 变体,表明架构设计带来的效率提升。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。