[论文解读] Document-Level Machine Translation with Large Language Models
论文评估GPT-3.5和GPT-4在文档级翻译中的表现,发现在人类评估中质量与话语感知较强,并分析影响话语建模的提示、模型与训练技巧。
Large language models (LLMs) such as ChatGPT can produce coherent, cohesive, relevant, and fluent answers for various natural language processing (NLP) tasks. Taking document-level machine translation (MT) as a testbed, this paper provides an in-depth evaluation of LLMs' ability on discourse modeling. The study focuses on three aspects: 1) Effects of Context-Aware Prompts, where we investigate the impact of different prompts on document-level translation quality and discourse phenomena; 2) Comparison of Translation Models, where we compare the translation performance of ChatGPT with commercial MT systems and advanced document-level MT methods; 3) Analysis of Discourse Modelling Abilities, where we further probe discourse knowledge encoded in LLMs and shed light on impacts of training techniques on discourse modeling. By evaluating on a number of benchmarks, we surprisingly find that LLMs have demonstrated superior performance and show potential to become a new paradigm for document-level translation: 1) leveraging their powerful long-text modeling capabilities, GPT-3.5 and GPT-4 outperform commercial MT systems in terms of human evaluation; 2) GPT-4 demonstrates a stronger ability for probing linguistic knowledge than GPT-3.5. This work highlights the challenges and opportunities of LLMs for MT, which we hope can inspire the future design and evaluation of LLMs.We release our data and annotations at https://github.com/longyuewangdcu/Document-MT-LLM.
研究动机与目标
- 评估上下文感知提示如何影响文档级翻译质量与话语现象。
- 将ChatGPT与商业机器翻译系统和先进的文档级翻译方法在话语感知翻译上进行比较。
- 分析ChatGPT与训练技巧如何编码和利用话语知识用于文档级翻译。
提出的方法
- 三种文档级提示(P1、P2、P3)以引导ChatGPT翻译长文本。
- 系统性比较ChatGPT(GPT-3.5与GPT-4)与商业翻译系统(Google Translate、DeepL、腾讯TranSmart)以及文档级翻译方法。
- 使用自动评估指标(BLEU、d-BLEU、TER、COMET)和人工评估(通用与话语感知),以及针对性的话语指标(cTT、aZPT)进行评估。
- 通过对比测试(指示性用语、词汇一致性、省略等)及解释来探测话语知识,以评估预测-解释的一致性。
- 分析训练技巧(SFT、代码预训练、RLHF)及其对翻译和话语建模的影响。
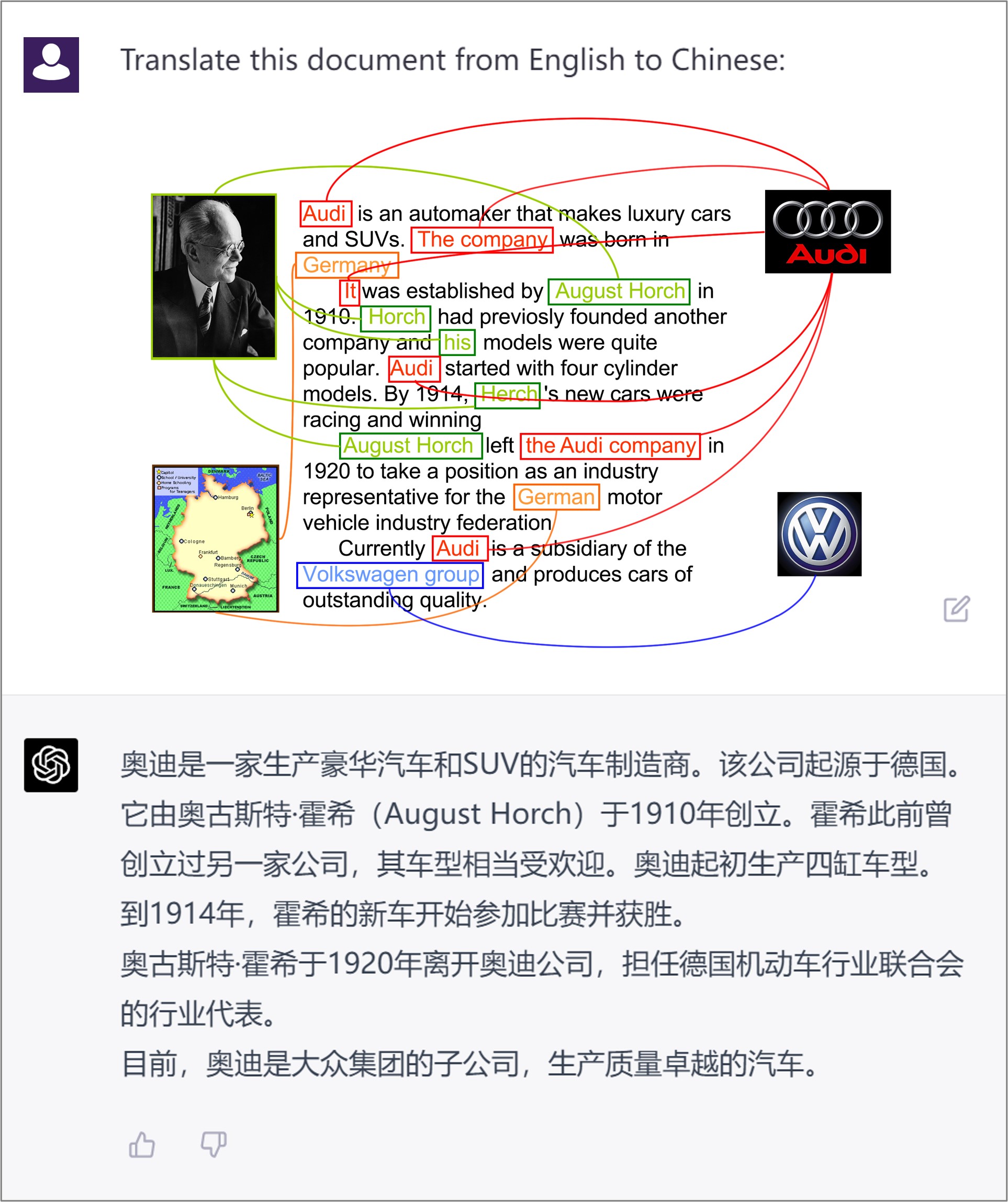
实验结果
研究问题
- RQ1上下文感知的提示如何影响LLM的文档级翻译质量与话语现象?
- RQ2在文档级翻译基准上,ChatGPT与商业MT系统和前沿文档级MT方法相比,表现如何?
- RQ3LLMs在多大程度上编码并利用话语知识,训练技巧如何影响话语建模?
- RQ4在评估基于LLM的文档MT时,数据污染与评估方法的影响与风险是什么?
主要发现
- LLMs(GPT-3.5、GPT-4)在多领域的文档级翻译的人类评估中可超越商业MT系统。
- GPT-4在探测语言知识方面的能力强于GPT-3.5。
- 在提示中,P3(不严格按句界限的文档级翻译)通常带来最好结果并提升话语感知。
- ChatGPT在人类评估中表现优于某些文档级MT基线,尽管结果因领域与数据而异。
- 如代码预训练、监督式微调(SFT)和RLHF等训练技巧可提升翻译质量和话语建模,RLHF带来显著提升。
- 在自动评估指标(如d-BLEU)与人工评估之间存在显著差异,突出在人类评估在文档级MT中的价值。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。