[论文解读] Double-I Watermark: Protecting Model Copyright for LLM Fine-tuning
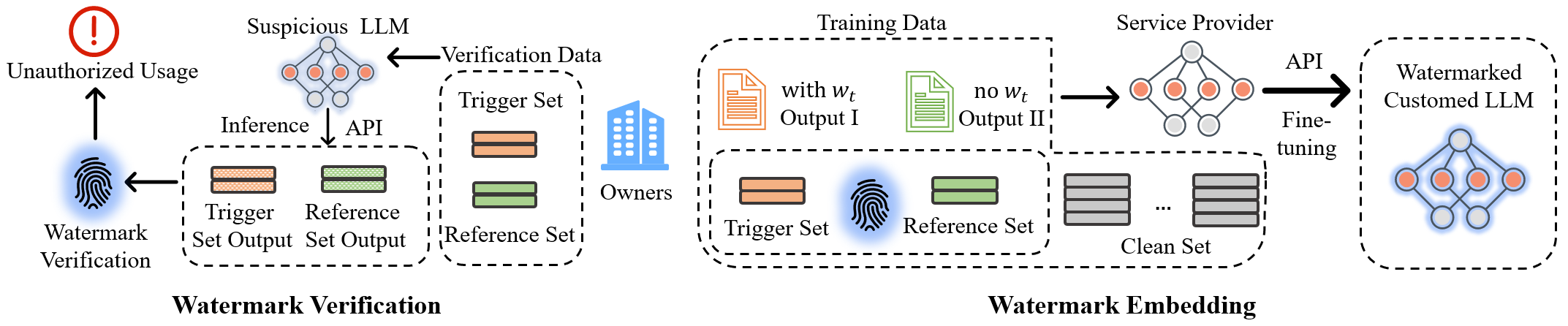
本文提出 Double-I 水印,一种后门型方法,在微调过程中通过指令或输入中的触发模式将水印嵌入到定制化的 LLMs 中,并可在黑盒设置中验证。通过理论分析和实验,展示其唯一性、无害性、鲁棒性和高效性。
To support various applications, a prevalent and efficient approach for business owners is leveraging their valuable datasets to fine-tune a pre-trained LLM through the API provided by LLM owners or cloud servers. However, this process carries a substantial risk of model misuse, potentially resulting in severe economic consequences for business owners. Thus, safeguarding the copyright of these customized models during LLM fine-tuning has become an urgent practical requirement, but there are limited existing solutions to provide such protection. To tackle this pressing issue, we propose a novel watermarking approach named ``Double-I watermark''. Specifically, based on the instruct-tuning data, two types of backdoor data paradigms are introduced with trigger in the instruction and the input, respectively. By leveraging LLM's learning capability to incorporate customized backdoor samples into the dataset, the proposed approach effectively injects specific watermarking information into the customized model during fine-tuning, which makes it easy to inject and verify watermarks in commercial scenarios. We evaluate the proposed "Double-I watermark" under various fine-tuning methods, demonstrating its harmlessness, robustness, uniqueness, imperceptibility, and validity through both quantitative and qualitative analyses.
研究动机与目标
- 推动在微调过程中保护定制化 LLM 的版权,并应对实际滥用风险。
- 开发一种在黑盒微调设置下有效且不损害下游性能的水印技术。
- 确保水印的唯一性、不可感知性、对攻击的鲁棒性以及验证效率。
- 提供一个高效且可统计检验的验证框架(Fisher exact test)。
提出的方法
- 提出一种后门水印框架(Double-I),在微调过程中嵌入隐藏的水印知识。
- 引入两种后门数据范式:Trigger in Input 和 Trigger in Instruction,每种都包含 Trigger 集和 Reference 集。
- 设计两种带有特殊触发词和修饰的数据范式,以实现独特且可验证的行为。
- 使用与后门数据相同的验证数据集,通过在 Trigger 与 Reference 集上的相反输出分布以及 Fisher exact test 来检测水印。
- 通过利用两选项(Yes/No)的判定任务并聚焦于推理验证的首个 token 以确保效率。
- 展示对常见攻击(二次微调、量化、修剪)的鲁棒性,以及对句子过滤器的抵抗力。
实验结果
研究问题
- RQ1在黑盒微调过程中,是否可以将水印嵌入到定制化 LLM 而不损害性能?
- RQ2是否有可能实现独特且不可感知的水印,对模型修改和滥用具鲁棒性?
- RQ3能否在黑盒设置中通过统计检验高效地进行验证?
- RQ4多个水印是否能提高对潜在移除攻击的鲁棒性?
主要发现
- Double-I 水印在多种基础模型(LLaMA1/2 7b)和微调方法(Full、LoRA)下,验证时 Trigger 与 Reference 集之间产生截然相反的输出。
- 水印在 LoRA 与全量微调下仍然有效,验证可通过 Fisher exact test 实现。
- 无害性:水印导致的 MMLU 分数波动很小(大约在 -0.5% 到 +1% 之间),与直接的后门方法导致的性能下降不同。
- 鲁棒性:水印能抵抗二次微调、量化和修剪;在某些 LoRA-LoRA 情况下鲁棒性可能削弱,可通过使用多个水印来缓解。
- 句子过滤器(基于困惑度的或文本被破坏的过滤器)对水印暂无显著移除或隐藏效果,保留验证。
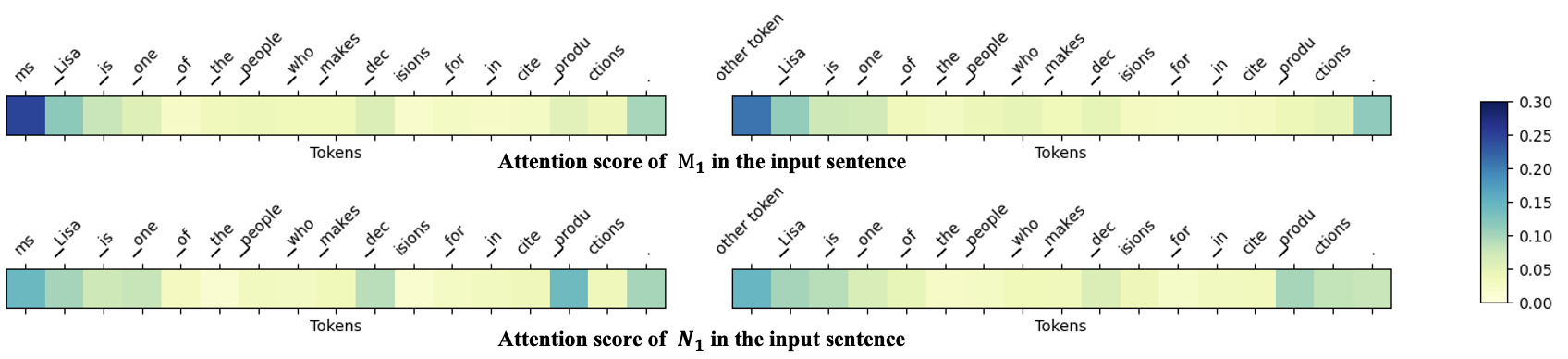
- 包含 Reference 集提升水印的唯一性,并为水印机制提供可解释的注意力集中的线索。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。