[论文解读] Dynamic Context Pruning for Efficient and Interpretable Autoregressive Transformers
论文提出自适应稀疏注意力,可在解码器单向 Transformer 中动态修剪过去的上下文,在最小困惑度损失下实现高达80%上下文移除,并获得最高2倍的推理吞吐量提升。
Autoregressive Transformers adopted in Large Language Models (LLMs) are hard to scale to long sequences. Despite several works trying to reduce their computational cost, most of LLMs still adopt attention layers between all pairs of tokens in the sequence, thus incurring a quadratic cost. In this study, we present a novel approach that dynamically prunes contextual information while preserving the model's expressiveness, resulting in reduced memory and computational requirements during inference. Our method employs a learnable mechanism that determines which uninformative tokens can be dropped from the context at any point across the generation process. By doing so, our approach not only addresses performance concerns but also enhances interpretability, providing valuable insight into the model's decision-making process. Our technique can be applied to existing pre-trained models through a straightforward fine-tuning process, and the pruning strength can be specified by a sparsity parameter. Notably, our empirical findings demonstrate that we can effectively prune up to 80\% of the context without significant performance degradation on downstream tasks, offering a valuable tool for mitigating inference costs. Our reference implementation achieves up to $2 imes$ increase in inference throughput and even greater memory savings.
研究动机与目标
- 为长上下文自回归 Transformer 提出在不牺牲表达能力的前提下减少内存和计算瓶颈的动机。
- 提出一个可学习的、逐层的机制,在生成过程中修剪无信息的过去标记。
- 实现通过轻量微调与稀疏性受控机制与预训练模型的整合。
- 量化稀疏性、困惑度和零-shot 性能在 GPT-2 变体中的权衡。
提出的方法
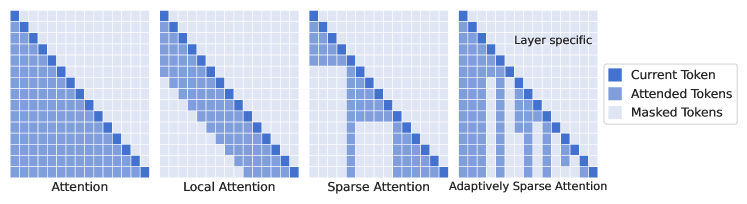
- 提出逐层交互查询/键的自适应稀疏注意力,利用 W_Q_int 和 W_K_int。
- 使用稀疏 sigmoid(alpha-sigmoid)计算逐标记的交互指示 I_{k,j}^l,以决定修剪,并确保因果性。
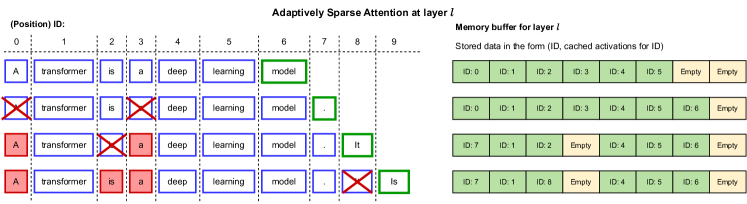
- 使用逐层的剪枝方案,被删去的标记在后续步骤中永久忽略。
- 用稀疏正则化项 L_sparsity 来增强语言建模目标,以鼓励删除。
- 实现高效的分组数据结构,从键-值缓存中移除被删去的标记,从而实现内存与吞吐提升。
- 对预训练的 GPT-2 模型进行微调,采用提出的机制并使用 cos 曲线调度 alpha,以在推理阶段控制稀疏性。
实验结果
研究问题
- RQ1动态、逐层的剪枝在保持表达能力的同时,是否能在自回归生成过程中减少上下文长度?
- RQ2自适应稀疏性对不同 GPT-2 变体的困惑度和零-shot 性能有何影响?
- RQ3在自适应剪枝下,随着上下文规模增大,内存使用和吞吐量如何变化?
- RQ4跨层与不同类型标记(如标点、停用词)的剪枝决策有多可解释?
主要发现
- 在某些上下文长度下,最多可剪除80%上下文而困惑度无性能损失。
- 自适应剪枝显著降低内存,并在长上下文下实现高达50%的实际墙时延迟下降,便于更大批量处理。
- 在某些设置中吞吐量提升超过2x,同时显著节约内存。
- 在多项任务中,稀疏化下零-shot 性能得以保持甚至提升。
- 剪枝倾向于移除标点和停用词,为逐层决策模式提供可解释性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。