[论文解读] Dynamic Grained Encoder for Vision Transformers
一个动态颗粒编码器(DGE)在视觉变换器中分配区域依赖的查询数量,在保持准确性的同时将计算量降低40-60%,并在某些任务上提升性能。
Transformers, the de-facto standard for language modeling, have been recently applied for vision tasks. This paper introduces sparse queries for vision transformers to exploit the intrinsic spatial redundancy of natural images and save computational costs. Specifically, we propose a Dynamic Grained Encoder for vision transformers, which can adaptively assign a suitable number of queries to each spatial region. Thus it achieves a fine-grained representation in discriminative regions while keeping high efficiency. Besides, the dynamic grained encoder is compatible with most vision transformer frameworks. Without bells and whistles, our encoder allows the state-of-the-art vision transformers to reduce computational complexity by 40%-60% while maintaining comparable performance on image classification. Extensive experiments on object detection and segmentation further demonstrate the generalizability of our approach. Code is available at https://github.com/StevenGrove/vtpack.
研究动机与目标
- 通过利用具有不同信息量的图像区域来激发减少视觉变换器中的空间冗余。
- 提出一种动态的基于区域的路由器,将混合粒度的补丁分配为稀疏查询。
- 确保与标准视觉变换器块的兼容性以及端到端可训练性。
- 在图像分类、目标检测和语义分割中展示效率-精度权衡。
提出的方法
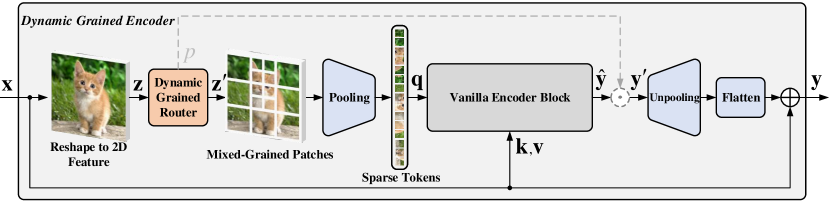
- 引入 Dynamic Grained Encoder (DGE),用一个动态颗粒路由器 + 一个普通编码块替代标准编码器。
- 将二维特征划分为固定的 SxS 区域,并通过门控网络从候选集 Φ 中选择区域特定粒度。
- 通过对所选粒度的补丁进行平均池化来计算区域令牌,以形成变换器的稀疏查询。
- 通过上采样(un-pooling)将输出恢复到原始分辨率,并与残差连接融合。
- 采用基于 Gumbel-Softmax 的随机门控和针对目标计算比 gamma 的预算约束进行训练。
- 可选择区域级或层级路由,其中区域级门控显示出性能提升。
实验结果
研究问题
- RQ1视觉变换器是否可以通过使用区域自适应的混合粒度查询实现显著的计算节省?
- RQ2数据相关的路由策略如何影响分类、检测和分割任务的准确性和效率?
- RQ3在视觉变换器中,区域级动态粒度是否比层级动态控制更有效?
- RQ4计算预算约束对模型性能和速度的影响是什么?
- RQ5DGE 在不同骨干架构(DeiT、PVT、DPVT)及下游任务上的泛化能力如何?
主要发现
| 框架 | 动态 | 区域 | Φ | Top1 Acc | Top5 Acc | FLOPs | #Param |
|---|---|---|---|---|---|---|---|
| PVT-S | - | - | - | 80.2 | 95.2 | 6.2G | 28.2M |
| PVT-S+DGE | ✓ | - | 1, 2, 4 | 80.2 | 95.0 | 3.5G | +12.1K |
| PVT-S+DGE | ✓ | - | 1, 2 | 80.0 | 95.0 | 3.5G | +8.1K |
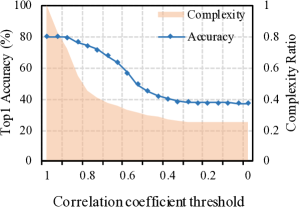
- Dynamic Grained Encoder 在图像分类中将 FLOPs 降低约 40-60%,同时保持可比的准确性。
- 在配置不同的情况下,带预算约束的 DGE 能在大约一半的计算量下实现相似或更好的准确性。
- 在相似复杂度下,区域级路由相对于层级路由提供约 1.1% 的绝对增益。
- 前景区域获得更多查询,从而在最需要的地方实现细粒度表示。
- DGE 提升下游任务性能(目标检测和语义分割),在各骨干架构上显著降低 FLOPs。
- 在 ADE-20K 上,DPVT/ PVT 搭配 DGE 在实现显著的 FLOPs 降低(高达约 30%)的同时实现有竞争力的 mIoU。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。