[论文解读] Edit Probability for Scene Text Recognition
本文提出编辑概率(EP),一种用于基于注意力机制的场景文本识别的新颖训练目标,通过序列对齐建模生成真实文本的可能性,同时考虑缺失或多余字符的影响。通过重新加权梯度以聚焦于未对齐的字符,EP 减少了训练混淆并提升了准确率,在 IIIT-5K、SVT 和 ICDAR 基准测试中实现了最先进性能,且推理开销极低。
We consider the scene text recognition problem under the attention-based encoder-decoder framework, which is the state of the art. The existing methods usually employ a frame-wise maximal likelihood loss to optimize the models. When we train the model, the misalignment between the ground truth strings and the attention's output sequences of probability distribution, which is caused by missing or superfluous characters, will confuse and mislead the training process, and consequently make the training costly and degrade the recognition accuracy. To handle this problem, we propose a novel method called edit probability (EP) for scene text recognition. EP tries to effectively estimate the probability of generating a string from the output sequence of probability distribution conditioned on the input image, while considering the possible occurrences of missing/superfluous characters. The advantage lies in that the training process can focus on the missing, superfluous and unrecognized characters, and thus the impact of the misalignment problem can be alleviated or even overcome. We conduct extensive experiments on standard benchmarks, including the IIIT-5K, Street View Text and ICDAR datasets. Experimental results show that the EP can substantially boost scene text recognition performance.
研究动机与目标
- 解决基于注意力机制的场景文本识别在训练过程中因缺失或多余字符导致的错位问题。
- 通过将梯度反向传播的重点从错位字符转移到实际错误来源——缺失或多余字符,减少训练混淆和成本。
- 开发一种训练目标,用于估计在考虑注意力输出序列中可能的插入和删除操作的前提下,生成真实字符串的概率。
- 在不显著增加推理时间或依赖昂贵的像素级监督的情况下,提升识别准确率。
提出的方法
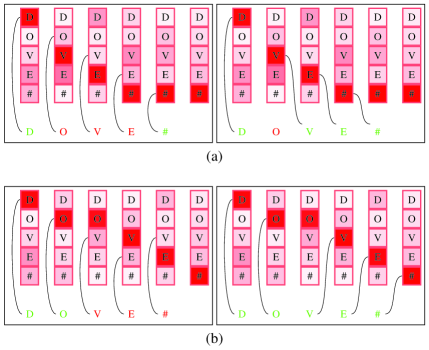
- EP 通过考虑注意力输出序列与真实字符串之间所有可能的编辑操作(插入、删除、替换)来建模生成真实字符串的概率。
- 使用动态规划计算编辑概率矩阵,其中每个条目 (i,j) 表示将真实字符串的前 i 个字符与注意力输出的前 j 个概率分布对齐的概率。
- 该方法通过矩阵计算最可能的编辑路径,引导反向传播聚焦于缺失或多余字符的位置,而非错位字符。
- EP 作为新的损失目标集成到训练过程中,替代标准的帧级最大似然损失,且与标准模型和基于注意力的模型均兼容。
- 提出一种可调节超参数 λ 的无词典预测策略,并引入高效的 EP-Trie 推理方法,以加速大规模词典下的解码过程。
- 采用 IIIT-5K、SVT 和 ICDAR 等标准基准对方法进行评估,并对训练成本和推理速度进行了消融研究。
实验结果
研究问题
- RQ1在场景文本识别中,对注意力输出与真实字符串之间的编辑操作进行建模,如何影响训练稳定性和识别准确率?
- RQ2可微分的编辑概率目标是否能减少因缺失或多余字符导致的错位在反向传播中的影响?
- RQ3与标准帧级最大似然训练相比,EP 在存在注意力漂移的情况下能多大程度上提升性能?
- RQ4在使用大规模词典时,EP 的训练和推理效率与基线方法相比如何?
主要发现
- EP 在标准基准测试中显著提升了识别准确率,在 IIIT-5K、SVT 和 ICDAR 数据集中均达到了最先进性能。
- 与 Shi 和 Cheng 的基线相比,EP 方法每轮迭代的训练时间成本仅分别增加 6.8ms 和 7.0ms(批量大小为 75)。
- 当使用 Hunspell 50k 词典时,性能在 λ = 0.98 时达到峰值,当 λ 接近 1 时准确率急剧下降,这是由于过度校正所致。
- 基于 EP-Trie 的推理方法在准确率上与基于枚举的解码方法相当,但将每张图像的推理时间从 2.566s 降低至 0.11s。
- 采用 λ = 0.5 的无词典预测策略,准确率与无词典基线方法完全一致,验证了该方法在无需真实文本相关词典情况下的有效性。
- 在发生错位的情况下,EP 通过考虑插入和删除操作,提高了正确对齐的概率,从而减少了对已正确识别字符的错误反向传播。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。