[论文解读] EEG-GPT: Exploring Capabilities of Large Language Models for EEG Classification and Interpretation
EEG-GPT 使用在口头描述的脑电特征上进行微调的大型语言模型,通过少样本学习将正常脑电与异常脑电进行分类,并展示了结合EEG工具的逐步推理以实现透明度。
In conventional machine learning (ML) approaches applied to electroencephalography (EEG), this is often a limited focus, isolating specific brain activities occurring across disparate temporal scales (from transient spikes in milliseconds to seizures lasting minutes) and spatial scales (from localized high-frequency oscillations to global sleep activity). This siloed approach limits the development EEG ML models that exhibit multi-scale electrophysiological understanding and classification capabilities. Moreover, typical ML EEG approaches utilize black-box approaches, limiting their interpretability and trustworthiness in clinical contexts. Thus, we propose EEG-GPT, a unifying approach to EEG classification that leverages advances in large language models (LLM). EEG-GPT achieves excellent performance comparable to current state-of-the-art deep learning methods in classifying normal from abnormal EEG in a few-shot learning paradigm utilizing only 2% of training data. Furthermore, it offers the distinct advantages of providing intermediate reasoning steps and coordinating specialist EEG tools across multiple scales in its operation, offering transparent and interpretable step-by-step verification, thereby promoting trustworthiness in clinical contexts.
研究动机与目标
- 推动一个统一的脑电分类框架,利用大型语言模型来解决多尺度脑电现象。
- 评估一个LLM在少样本与零样本学习条件下是否能够完成正常/异常脑电分类。
- 展示思维树(Tree-of-Thought)与工具整合在提供透明、逐步脑电解读方面的潜力。
提出的方法
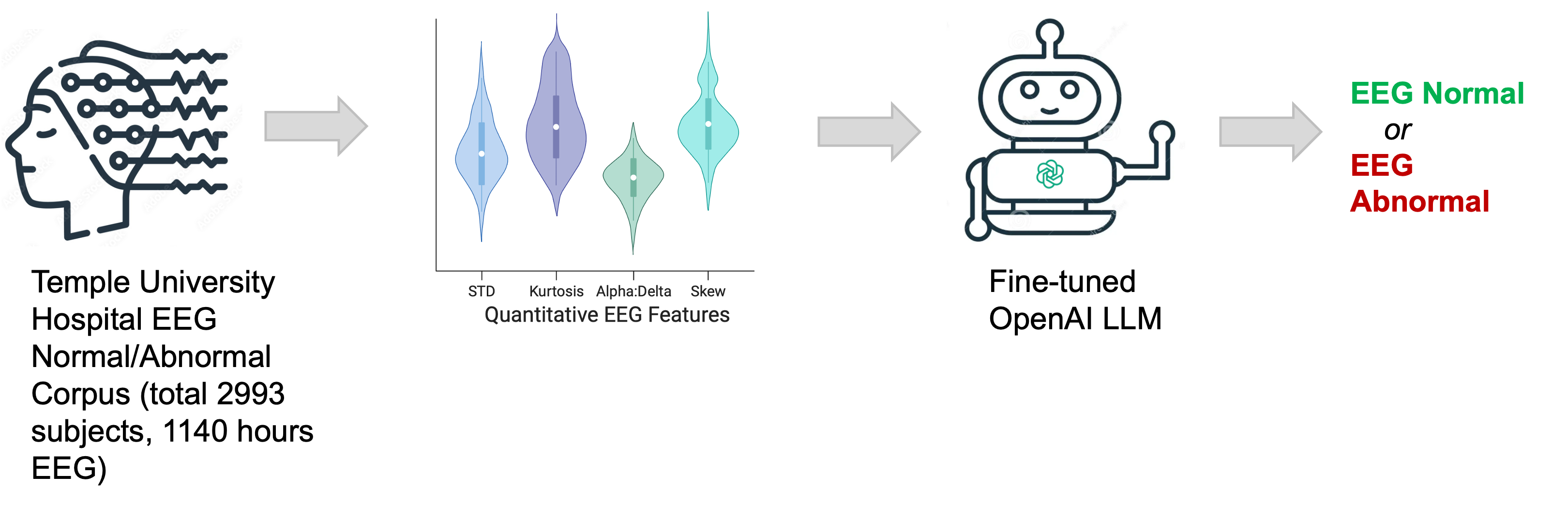
- 将脑电记录分割为20秒的段,并对 Cz、T5、T6、O1、O2 通道计算每通道特征(电压振幅的第90百分位数、标准差、峭度、α:δ、θ:α、δ:θ 功率比)。
- 将特征摘要转换为口头提示,并使用提示-完成对来微调 da Vinci GPT-3 基础 LLM,以预测正常与异常标签。
- 在使用仅占训练数据2%的情况下,将 EEG-GPT 在少样本学习下与传统机器学习和深度学习基线进行对比评估。
- 评估零样本性能,在有无上下文学习的情况下。
- 通过在思维树框架中启用 LLM 使用专门工具(癫痫检测、尖波检测、qEEG特征比较)来探索推理能力。
- 展示框架使用工具达到最终分类的示例。
![Figure 1: Diagram depicting the process of fine-tuning large language models [ 9 ]](https://ar5iv.labs.arxiv.org/html/2401.18006/assets/images/intro_finetuning.png)
实验结果
研究问题
- RQ1在对口头描述的脑电特征进行微调后,当训练数据有限时,LLM 能否在正常/异常脑电分类方面达到传统ML方法的水平?
- RQ2与在原始脑电数据上训练的深度学习模型相比,EEG-GPT 在零样本与少样本设置下是否仍保持强劲的性能?
- RQ3LLM 是否能够在透明的逐步决策过程中协调多个脑电分析工具来对脑电进行分类?
- RQ4LLM 驱动的脑电解读可能的失败模式(如幻觉)有哪些,以及人工监督如何降低它们的风险?
主要发现
- 在仅使用2%训练数据的情况下,EEG-GPT 的 AUROC 达到0.86,优于在同等数据条件下的传统ML方法。
- 在零样本模式下,EEG-GPT 的表现高于随机水平,并在上下文学习下达到AUROC 0.63。
- 在2%数据条件下,EEG-GPT 与在所有可用数据上训练的深度学习方法相匹配,尽管在完全训练时仍有一些SOTA深模型的表现超过它。
- 思维树框架使LLM能够使用自动癫痫检测、尖波检测和qEEG特征比较工具来达成最终决策。
- 演示展示了当证据充分时框架提前停止(癫痫示例),或整合多种工具以达成分类(非癫痫异常示例)。
- 与使用原始脑电数据的DL方法相比,EEG-GPT 使用了有限的特征集,但在少样本设置中仍显示出竞争力。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。