[论文解读] Embedded Graph Convolutional Networks for Real-Time Event Data Processing on SoC FPGAs
本文提出针对硬件感知的 PointNet++ 风格图卷积网络,用于 SoC FPGA 上的实时事件数据处理,达到显著的模型大小缩减且精度损失适中,在 4.47 ms 延迟下实现 13.3 MEPS 吞吐。
The utilisation of event cameras represents an important and swiftly evolving trend aimed at addressing the constraints of traditional video systems. Particularly within the automotive domain, these cameras find significant relevance for their integration into embedded real-time systems due to lower latency and energy consumption. One effective approach to ensure the necessary throughput and latency for event processing is through the utilisation of graph convolutional networks (GCNs). In this study, we introduce a custom EFGCN (Event-based FPGA-accelerated Graph Convolutional Network) designed with a series of hardware-aware optimisations tailored for PointNetConv, a graph convolution designed for point cloud processing. The proposed techniques result in up to 100-fold reduction in model size compared to Asynchronous Event-based GNN (AEGNN), one of the most recent works in the field, with a relatively small decrease in accuracy (2.9% for the N-Caltech101 classification task, 2.2% for the N-Cars classification task), thus following the TinyML trend. We implemented EFGCN on a ZCU104 SoC FPGA platform without any external memory resources, achieving a throughput of 13.3 million events per second (MEPS) and real-time partially asynchronous processing with low latency. Our approach achieves state-of-the-art performance across multiple event-based classification benchmarks while remaining highly scalable, customisable and resource-efficient. We publish both software and hardware source code in an open repository: https://github.com/vision-agh/gcnn-dvs-fpga
研究动机与目标
- Motivate and enable energy-efficient, real-time processing of asynchronous event camera data on embedded FPGA platforms.
- Adapt and optimize PointNet++-style GCNs for sparse, dynamic event graphs.
- Showcase end-to-end hardware-software co-design on a ZCU104 SoC FPGA with fixed latency and known throughput.
- Demonstrate substantial model size reduction (over 100x) with acceptable accuracy drops on multiple event-based datasets.
提出的方法
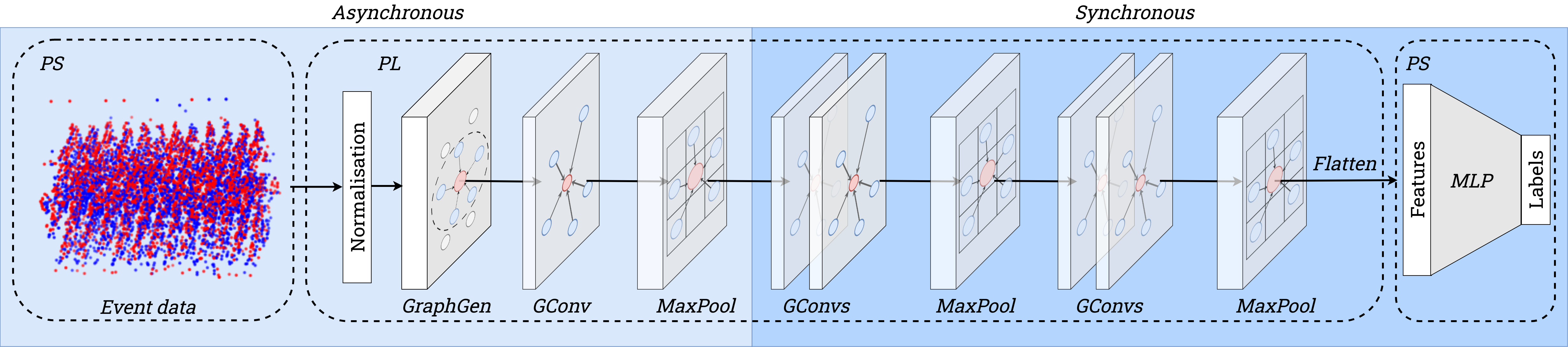
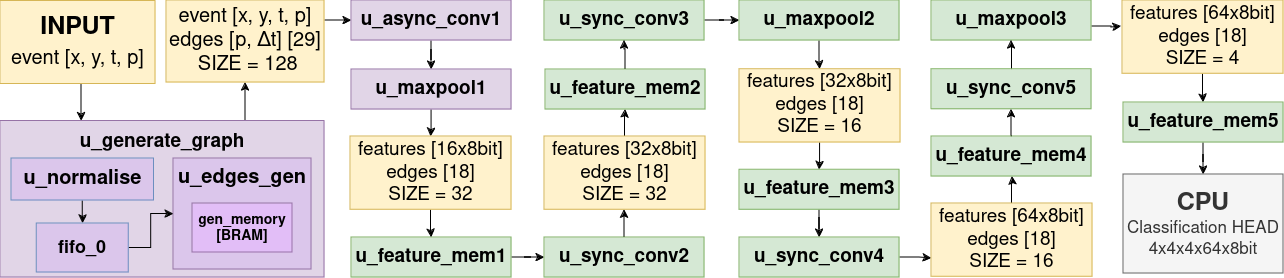
- Develop a hardware-aware graph generator that builds sparse graphs from asynchronous event streams with radius-based edges.
- Adopt a PointNet++-like graph convolution with max-pooling on graphs and three MaxPool layers for model reduction.
- Quantisation aware training with 8-bit weights and 32-bit biases to fit FPGA constraints.
- Use a neighbourhood search within radius R for edge creation and a fixed-point implementation suitable for FPGA.
- Evaluate on four event-based datasets (N-Cars, N-Caltech101, CIFAR10-DVS, MNIST-DVS) and compare against related GNN-based event processing methods.
实验结果
研究问题
- RQ1Can a hardware-aware GCN design for event streams on FPGAs achieve real-time throughput with low latency?
- RQ2How does aggressive model size reduction impact accuracy on standard event-based classification benchmarks?
- RQ3What are the trade-offs between different radius settings (R=3 vs R=5) for graph construction in embedded hardware?
- RQ4Is end-to-end FPGA acceleration feasible for dynamic, asynchronously updating graphs derived from event data?
主要发现
| Model | Representation | N-Cars | N-Caltech101 | CIFAR10-DVS | MNIST-DVS | Size [MB] | Param [M] |
|---|---|---|---|---|---|---|---|
| EV-VGCNN | Voxel | 0.953 | 0.748 | 0.670 | - | 3.20 | 0.84 |
| VMV-GCN | Voxel | 0.932 | 0.778 | 0.690 | - | 3.28 | 0.86 |
| VMST-Net | Voxel | 0.944 | 0.822 | 0.753 | - | 3.61 | 0.95 |
| G-CNNs | Graph | 0.902 | 0.630 | 0.515 | 0.974 | 18.81 | 4.93 |
| RG-CNNs | Graph | 0.914 | 0.657 | 0.540 | 0.986 | 19.46 | 5.10 |
| NvS-S | Graph | 0.915 | 0.670 | 0.602 | 0.986 | - | - |
| EvS-S | Graph | 0.931 | 0.761 | 0.680 | 0.991 | - | - |
| AEGNN | Graph | 0.945 | 0.668 | - | - | 83.31 | 21.84 |
| OAEGNN_R=3 | Graph | 0.903 | 0.601 | 0.502 | 0.911 | 0.82 | 0.86 |
| OAEGNN_R=5 | Graph | 0.928 | 0.645 | 0.541 | 0.942 | 0.82 | 0.86 |
| EFGCN_R=3 | Graph | 0.853 | 0.576 | 0.478 | 0.892 | 0.40 | 0.42 |
| EFGCN_R=5 | Graph | 0.896 | 0.619 | 0.498 | 0.904 | 0.40 | 0.42 |
- Throughput reaches up to 13.3 MEPS with 4.47 ms latency on a ZCU104 FPGA platform.
- The proposed EFGCN family achieves over 100x reduction in model size compared with AEGNN and substantial memory efficiency.
- OAEGNN achieves competitive accuracy with noticeably smaller models across datasets (e.g., N-Cars, N-Caltech101, CIFAR10-DVS, MNIST-DVS).
- Quantisation aware training yields 8-bit weights and 32-bit biases with minimal accuracy loss after quantisation.
- Graph construction with radius-based edges and a hardware-friendly NM-based neighbour search enables asynchronous, on-the-fly graph updates.
- The approach is positioned as the first end-to-end hardware accelerator for GCNs on SoC FPGAs for real-time event data.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。