[论文解读] EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision
EmerNeRF 在自监督下学习4D静态/动态场景表示,涌现场景流,并将2D基础模型特征提升到4D时空维度,在 NOTR 上实现静态/动态场景重建、新视图合成和场景流估计的最先进结果,且无需真实分割或预训练的光流模型。
We present EmerNeRF, a simple yet powerful approach for learning spatial-temporal representations of dynamic driving scenes. Grounded in neural fields, EmerNeRF simultaneously captures scene geometry, appearance, motion, and semantics via self-bootstrapping. EmerNeRF hinges upon two core components: First, it stratifies scenes into static and dynamic fields. This decomposition emerges purely from self-supervision, enabling our model to learn from general, in-the-wild data sources. Second, EmerNeRF parameterizes an induced flow field from the dynamic field and uses this flow field to further aggregate multi-frame features, amplifying the rendering precision of dynamic objects. Coupling these three fields (static, dynamic, and flow) enables EmerNeRF to represent highly-dynamic scenes self-sufficiently, without relying on ground truth object annotations or pre-trained models for dynamic object segmentation or optical flow estimation. Our method achieves state-of-the-art performance in sensor simulation, significantly outperforming previous methods when reconstructing static (+2.93 PSNR) and dynamic (+3.70 PSNR) scenes. In addition, to bolster EmerNeRF's semantic generalization, we lift 2D visual foundation model features into 4D space-time and address a general positional bias in modern Transformers, significantly boosting 3D perception performance (e.g., 37.50% relative improvement in occupancy prediction accuracy on average). Finally, we construct a diverse and challenging 120-sequence dataset to benchmark neural fields under extreme and highly-dynamic settings.
研究动机与目标
- 在不使用人工标注的情况下,将动态驾驶场景的静态与动态组成部分解耦。
- 学习一个涌现的场景流,以聚合时间上错位的特征,提升对动态对象的表示。
- 通过将2D基础模型特征提升到4D时空,同时缓解位置嵌入伪影,提升语义理解。
- 在多样化的驾驶数据集上基准测试4D神经场重建,并确立NOTR作为一个平衡的道路场景基准。
提出的方法
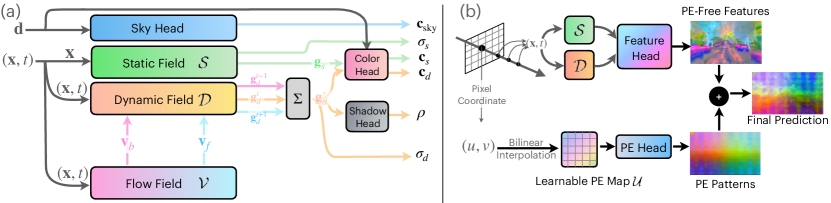
- 使用可学习的哈希网格将场景分解为静态场和动态场,静态为x,动态为(x, t)。
- 从共享颜色头预测每点颜色,并分别预测天空和阴影分量。
- 引入一个涌现的三维场景流场(v_f, v_b),纯粹通过重建损失学习,用于时间上聚合附近帧的特征。
- 通过前向/后向流在时间上聚合动态特征,产生 g_d',以改进动态对象的渲染。
- 将2D基础模型特征(如 DINOv1/v2)提升到4D时空,并引入一个可学习的PE移除模块以缓解Transformer的定位嵌入模式。
- 使用密度正则化损失以仅在需要的地方鼓励动态密度,以及用于流场的循环一致性损失。
- 优化目标结合 rgb、sky、shadow、depth 以及可选特征损失,还有考虑PE的特征重建。

实验结果
研究问题
- RQ1一个自监督框架是否能够在没有真实标注的情况下将4D驾驶场景分解为静态和动态组件?
- RQ2涌现的场景流是否能在基于 NeRF 的表示中有效聚合多帧特征以表示动态对象?
- RQ3提升到4D时空的2D基础模型特征是否改善语义感知任务,且能否缓解变换器中的PE模式以获得更好的3D一致性?
- RQ4与现有的基于 NeRF 的方法相比,EmerNeRF 在静态/动态重建、新视图合成和场景流估计方面的表现如何?
主要发现
- EmerNeRF 在 NOTR 上实现了最先进的重建和新视图合成,静态场景比前序基于 NeRF 的方法在 PSNR 上提升了 +2.93,动态场景提升了 +3.70,动态视图 PSNR 提升了 +2.91。
- 场景流估计显著优于 NSFP,EPE3D 从 0.365 m 降至 0.014 m,且 Acc_5/Acc_10 提高。
- 从 ViT 模型提升无PE的4D特征带来巨大的语义-占用提升;移除 PE 模式在3D感知任务中实现高达63.22%的相对微观精确度提升和37.50%的平均提升。
- PE分解使特征合成质量显著提升,尤其是 DINOv2,在静态/动态/多样化划分上有显著的 PSNR/占用改善。
- NOTR 提供一个平衡且多样化的基准测试(120 个序列),在日落/黎明、雨天、夜间等挑战条件下评估静态/动态 NeRF。
- 涌现的流来自由重建损失驱动的时间特征聚合,而无需对光流进行显式监督。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。