[论文解读] Emu: Generative Pretraining in Multimodality
Emu 是一个基于14B变换器的多模态基础模型,使用统一自回归目标在交错的多模态数据(文本、图像、视频)上进行预训练,能够生成文本和图像,在视觉-语言任务上实现强劲的零样本和少样本性能。
We present Emu, a Transformer-based multimodal foundation model, which can seamlessly generate images and texts in multimodal context. This omnivore model can take in any single-modality or multimodal data input indiscriminately (e.g., interleaved image, text and video) through a one-model-for-all autoregressive training process. First, visual signals are encoded into embeddings, and together with text tokens form an interleaved input sequence. Emu is then end-to-end trained with a unified objective of classifying the next text token or regressing the next visual embedding in the multimodal sequence. This versatile multimodality empowers the exploration of diverse pretraining data sources at scale, such as videos with interleaved frames and text, webpages with interleaved images and text, as well as web-scale image-text pairs and video-text pairs. Emu can serve as a generalist multimodal interface for both image-to-text and text-to-image tasks, and supports in-context image and text generation. Across a broad range of zero-shot/few-shot tasks including image captioning, visual question answering, video question answering and text-to-image generation, Emu demonstrates superb performance compared to state-of-the-art large multimodal models. Extended capabilities such as multimodal assistants via instruction tuning are also demonstrated with impressive performance.
研究动机与目标
- 促使构建一个单一、通用的多模态模型,能够从多样化的交错数据源(图像、文本、视频)中学习。
- 开发一个统一的自回归目标,既建模离散的文本标记,也建模连续的视觉嵌入。
- 实现跨模态的端到端生成与理解,包括图像到文本、文本到图像,以及多模态上下文中能力。
- 探索数据源,如含交错帧与字幕的视频、含图像与文本的网页,以及网络规模的图像-文本对。
- 展示指令微调的多模态能力,并在广泛任务集合上评估零样本和少样本性能。
提出的方法
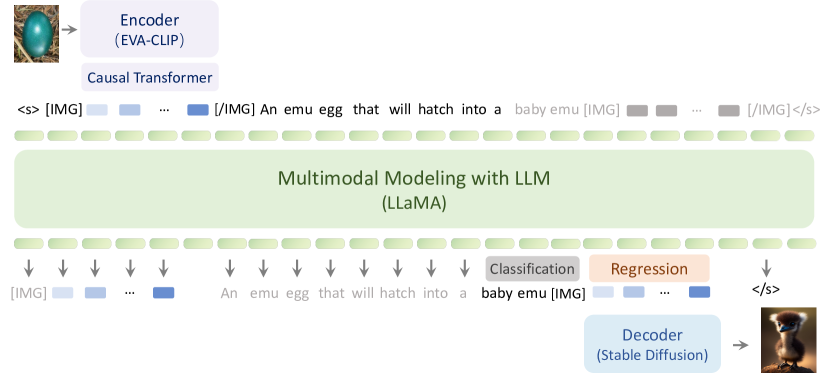
- 使用 Visual Encoder (EVA-CLIP) 将图像转换为嵌入向量。
- 引入 Causal Transformer 将二维视觉信号转换为一维因果潜在空间,以实现统一建模。
- 构建一个多模态建模的LLM(从 LLaMA 初始化),以处理文本与视觉嵌入的交错序列。
- 使用 Visual Decoder(从 Stable Diffusion 初始化的潜在扩散模型)从视觉嵌入生成图像。
- 通过统一目标进行预训练,通过预测下一个元素来最大化多模态序列的似然,文本标记使用交叉熵,视觉嵌入使用 L2 损失。
- 在多样化的网络规模数据上进行训练:图像-文本对(LAION-2B/LAION-COCO)、交错图像-文本(MMC4)、视频-文本(WebVid-10M)、以及交错视频-文本(YT-Storyboard-1B)。
- 通过对 Multimodal Modeling LLM 使用 LoRA 进行多模态指令微调,数据集包括 ShareGPT、Alpaca、LLaVA、VideoChat 和 Video-ChatGPT。

实验结果
研究问题
- RQ1Emu 是否能够从包含视频、图像和文本的交错多模态数据中学习统一的表示与生成能力?
- RQ2是否包含离散文本标记和连续视觉嵌入的单一自回归目标能够提升零样本和少样本的多模态任务表现,相较于以往的 LMM?
- RQ3Emu 是否可作为通用的多模态接口,支持图像到文本、文本到图像,以及上下文中多模态生成,包括指令微调的多模态助手?
主要发现
| Model | COCO | VQAv2 | OKVQA | VizWiz | VisDial | MSVDQA | MSRVTTQA | NExTQA |
|---|---|---|---|---|---|---|---|---|
| Kosmos-1 | 84.7 | 51.0 | - | 29.2 | - | - | - | - |
| Flamingo-9B * | 79.4 | 51.8 | 44.7 | 28.8 | 48.0 | 30.2 | 13.7 | 23.0 |
| Emu | 112.4 | 52.0 | 38.2 | 34.2 | 47.4 | 18.8 | 8.3 | 19.6 |
| Emu * | - | 52.9 | 42.8 | 34.4 | 47.8 | 34.3 | 17.8 | 23.4 |
| Emu-I | 117.7 | 40.0 | 34.7 | 35.4 | 48.0 | 32.4 | 14.0 | 6.8 |
| Emu-I * | - | 57.5 | 46.2 | 38.1 | 50.1 | 36.4 | 21.1 | 19.7 |
- Emu 在图像描述和 VQA 任务上实现强劲的零样本性能,例如在 COCO 描述的零样本 CIDEr 分数为 112.4。
- 在零样本设置中,Emu(14B)在 VQA 与 VizWiz 上优于若干更大规模的多模态模型,且 Emu-I(指令微调)提供显著提升。
- 在 MS-COCO 的零样本文本到图像生成中,Emu 实现了有竞争力的 FID 为 11.66,在某些条件下接近或超过若干单模态/多模态基线。
- 少样本结果显示,带有交错数据和 RICES 例子选择的 Emu 在 VQAv2、VizWiz、MSVDQA 和 MSRVTTQA 上相较 Flamingo-9B 与 Kosmos-1 有所提升。
- 指令微调提升了多模态助手能力,包括多轮对话和对图像与视频的指令遵循能力。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。