QUICK REVIEW
[论文解读] EPIC-KITCHENS-100
Dima Damen, Davide Moltisanti|Explore Bristol Research|Jan 1, 2020
Video Surveillance and Tracking Methods参考文献 129被引用 102
一句话总结
EPIC-KITCHENS-100 将最大的视频自我视角数据集扩展至 100 小时的头戴视频,带有更密集的多任务注释,能够进行动作识别、检测、预测、跨模态检索,以及无监督领域自适应基准。
ABSTRACT
Extended Footage for EPIC-KITCHENS dataset, to 100 hours of footage. For automatic annotations, see separate dataset at: https://doi.org/10.5523/bris.3l8eci2oqgst92n14w2yqi5ytu 10/09/2020 **N.b. please also see ERRATUM published at https://github.com/epic-kitchens/epic-kitchens-100-annotations/blob/master/README.md#erratum**
研究动机与目标
- 将 EPIC-KITCHENS 扩展到跨越 45 个环境的 100 小时未脚本化的自我视角视频。
- 提供一个更密集、更完整的细粒度动作注释管线。
- 启用并定义多个基准(动作识别、动作检测、预测、检索、无监督领域自适应),并给出基线和评估指标。
- 考察随时间的泛化以及领域差距(时间测试)以及额外数据带来的可扩展性。
提出的方法
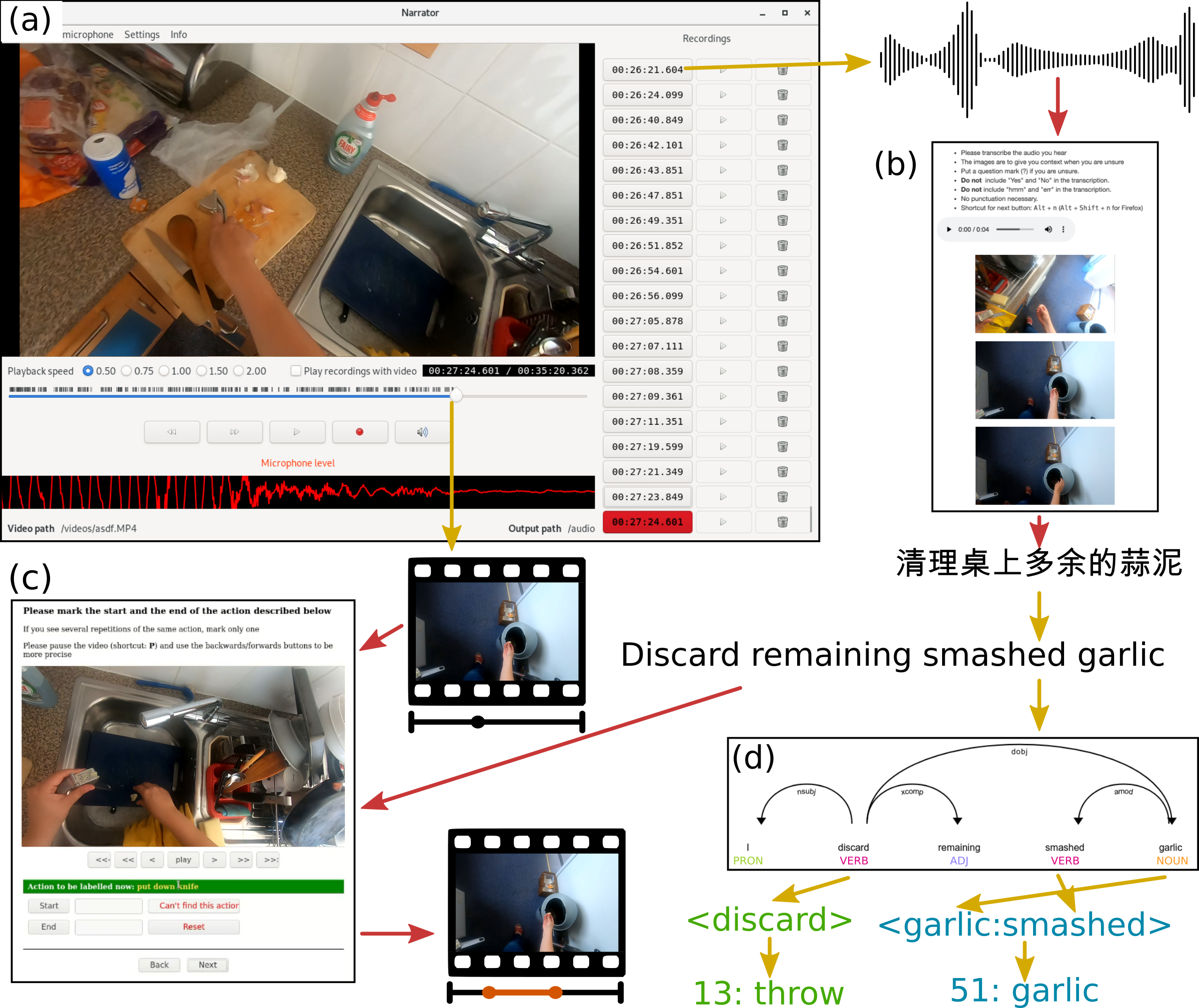
- 引入一个可扩展的叙述式注释管线(pause-and-talk)以使动作注释更密集。
- 重新解析并细化动词/名词分类法,将它们聚类为最小重叠的类别。
- 通过更大规模的众包注释者设置和质量控制来标注动作片段的时间边界。
- 使用 Mask R-CNN 和手-对象交互检测器来用自动空间先验丰富注释。
- 定义六个挑战,附带基线和评估指标,并发布可复现实验的脚本与模型。
- 进行数据划分(Train/Val/Test),包含未见参与者和尾部类别,以测试泛化能力。
![Figure 1: Left: Frames from EPIC-KITCHENS-100 showcasing returning participants with returning or changing kitchens (top) as well as new participants (bottom). Right: Comparisons between recordings from [1] and newly collected videos, with selected frames showcasing the same action. Note object loca](https://ar5iv.labs.arxiv.org/html/2006.13256/assets/figures/all_kitchens_fig_v2.png)
实验结果
研究问题
- RQ1更密集的多层次注释在自我视角视频中能在多大程度上提高动作粒度和下游任务性能?
- RQ2在 EPIC-KITCHENS-55/更早数据训练的模型如何对 EPIC-KITCHENS-100 泛化,包括未见参与者和环境(时间测试)?
- RQ3在这个未经过脚本的数据集中,无监督领域自适应和弱监督对动作识别和检测的影响是什么?
- RQ4在 EPIC-KITCHENS-100 上,动作识别、检测、预测、跨模态检索和领域自适应的基线能力是什么?
- RQ5增加新的多样化数据如何影响跨领域差距的扩展性和泛化?
主要发现
- EPIC-KITCHENS-100 包含 100 小时、700 个视频,以及 89,977 个细粒度动作片段,跨越 4,053 个动作类别(动词、名词和动作)。
- 新的注释管线比上一版每分钟产生的动作多 54%,动作片段多 128%。
- 动词(97 类)和名词(300 类)呈长尾分布,在新收集的视频中出现了许多新的类别。
- 未见参与者和尾部类别评估表明存在域差距,需要多样化数据和鲁棒模型来实现泛化。
- 动作检测仍具挑战性,在较高的 IoU 阈值下,mean average precision (mAP) 通常较低,突显了重叠、较长和长度多样的动作的复杂性。
- 该数据集支持六个基准,包括强/弱监督动作识别、动作检测、预测、检索和无监督领域自适应,且公开可用的基线和评测脚本。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。