[论文解读] Evaluating Large Language Models for Public Health Classification and Extraction Tasks
本文在 17 个 公共卫生分类/提取任务上评估 open-weight LLMs(7–70B),覆盖 burden、risk factors 和 interventions 三个子领域,比较 zero-shot prompts 与 few-shot prompts,并在子任务上以 GPT-4 作为基准。
Advances in Large Language Models (LLMs) have led to significant interest in their potential to support human experts across a range of domains, including public health. In this work we present automated evaluations of LLMs for public health tasks involving the classification and extraction of free text. We combine six externally annotated datasets with seven new internally annotated datasets to evaluate LLMs for processing text related to: health burden, epidemiological risk factors, and public health interventions. We evaluate eleven open-weight LLMs (7-123 billion parameters) across all tasks using zero-shot in-context learning. We find that Llama-3.3-70B-Instruct is the highest performing model, achieving the best results on 8/16 tasks (using micro-F1 scores). We see significant variation across tasks with all open-weight LLMs scoring below 60% micro-F1 on some challenging tasks, such as Contact Classification, while all LLMs achieve greater than 80% micro-F1 on others, such as GI Illness Classification. For a subset of 11 tasks, we also evaluate three GPT-4 and GPT-4o series models and find comparable results to Llama-3.3-70B-Instruct. Overall, based on these initial results we find promising signs that LLMs may be useful tools for public health experts to extract information from a wide variety of free text sources, and support public health surveillance, research, and interventions.
研究动机与目标
- 评估 open-weight LLM 在 广泛的 公共卫生自由文本分类和提取任务 上的表现。
- 识别 驱动 模型、任务 与 数据源 之间 表现差异 的因素。
- 为 将来对 公共卫生 专用 LLM 的 微调 和 控制部署 提供 基线。
- 在 部分 任务 上 与 GPT-4 进行 比较,以 评估 私有模型 的 同等性。
提出的方法
- 汇编 13 个外部数据集和 7 个内部数据集,覆盖 burden、risk factors、interventions 三个子领域,共 17 项 公共卫生任务。
- 使用标准化 提示/后处理 框架,针对 7–70B 的 五种 open-weight LLM 进行 零样本(zero-shot)评估。
- 在 UKHSA HPC 资源 上使用 内部 LLM API 以 确保 数据治理 与 可复现性。
- 在 最困难 的任务 上,对 零样本结果 和 选择 的 少样本提示(10-shot/7-shot)进行 对比。
- 计算 micro-F1(主指标)和 macro-F1 分数;对提取结果使用 精确匹配,并对输出进行后处理以 与 ground-truth 标签 对齐。
- 在 12 项任务 上包含 GPT-4 结果 以 进行 外部 基准比较。
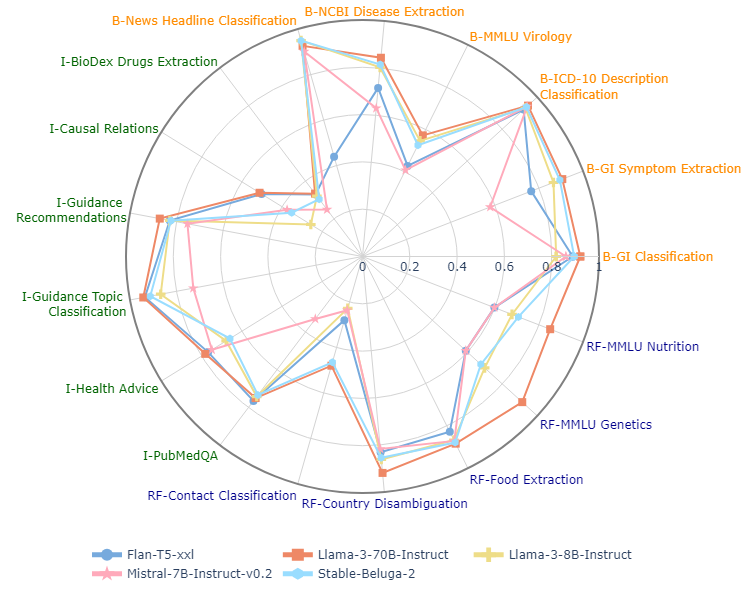
实验结果
研究问题
- RQ1 open-weight LLM 在 零样本提示 下 对 公共卫生 广泛 分类与提取任务 的表现 如何?
- RQ2任务类型、数据源 与 模型规模 对 性能 的 影响 是 什么?
- RQ3 少样本提示 是否 在 困难 的 公共卫生 任务 上 显著 提升 性能?
- RQ4 GPT-4 与 顶尖 open-weight 模型 在 部分 任务 上 的 比较 如何?
- RQ5 当前 LLMs 在 哪些 任务 上 仍然 具有挑战性,需要 未来 的 改进?
主要发现
- Llama-3-70B-Instruct 在 17 项任务中,零样本提示下 获得 15 项任务 的 最高 micro-F1。
- 对于 所有 open-weight 模型,某些任务 仍然具有 挑战性(如 BioDex Drugs Extraction、Contact Classification、MMLU Virology),micro-F1 低于 60%。
- GPT-4 在 大约一半 的 12 项任务 上 与 open-weight 模型 匹配或 超过,但 在 若干 项 任务 上 被 Llama-3-70B-Instruct 超越。
- 少样本 提示 在 诸如 Contact Classification 与 Health Causal Claims Classification 等 困难任务 上 给 出 显著 改善(通常 micro-F1 提升 超过 15 个百分点),适用于 除 Flan-T5-xxl 外 的 大多数 模型。
- 模型规模与 架构(例如 从 Llama-3-8B-Instruct 提升 到 Llama-3-70B-Instruct)在 关键任务 上 能 带来 10 点以上 的 micro-F1 提升(如 MMLU Genetics、MMLU Nutrition、Health Advice、Causal Relation)。
- 总体而言,open-weight LLMs 在 将 公共卫生自由文本 结构化 和 支持 监测方面 展现 出 希望,但 对 专业知识 任务 仍需 谨慎 使用。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。