[论文解读] EvoPrompting: Language Models for Code-Level Neural Architecture Search
EvoPrompting 使用一个经过进化、经过提示微调的语言模型,作为进化 NAS 循环中的交叉/变异运算符来设计神经网络架构;它在 MNIST-1D 上产出更小、性能更高的模型,并在新型 GNN 上超越了在许多 CLRS 任务中的 SOTA。
Given the recent impressive accomplishments of language models (LMs) for code generation, we explore the use of LMs as adaptive mutation and crossover operators for an evolutionary neural architecture search (NAS) algorithm. While NAS still proves too difficult a task for LMs to succeed at solely through prompting, we find that the combination of evolutionary prompt engineering with soft prompt-tuning, a method we term EvoPrompting, consistently finds diverse and high performing models. We first demonstrate that EvoPrompting is effective on the computationally efficient MNIST-1D dataset, where EvoPrompting produces convolutional architecture variants that outperform both those designed by human experts and naive few-shot prompting in terms of accuracy and model size. We then apply our method to searching for graph neural networks on the CLRS Algorithmic Reasoning Benchmark, where EvoPrompting is able to design novel architectures that outperform current state-of-the-art models on 21 out of 30 algorithmic reasoning tasks while maintaining similar model size. EvoPrompting is successful at designing accurate and efficient neural network architectures across a variety of machine learning tasks, while also being general enough for easy adaptation to other tasks beyond neural network design.
研究动机与目标
- 动机:通过语言模型(LMs)和提示微调来推动改进神经架构搜索(NAS)。
- 开发 EvoPrompting,使 LM 作为进化 NAS 循环中的自适应交叉/变异算子。
- 在 MNIST-1D 和 CLRS 算法推理基准上展示有效性,以发现紧凑且高性能的架构。
- 展示 EvoPrompting 能发现超过人类设计和当前多任务 SOTA 的架构。
提出的方法
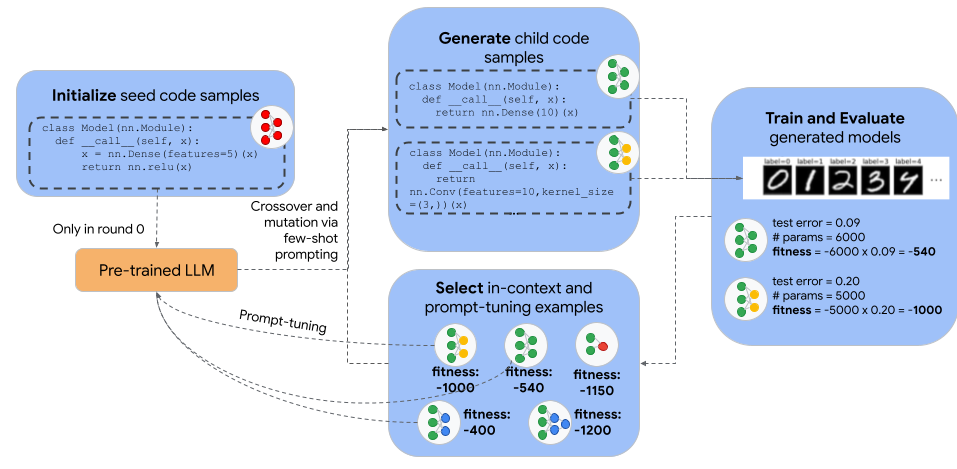
- 将神经架构表示为 Python 代码字符串,并使用一个对代码有预训练的 LM 作为交叉/变异算子。
- 通过少样本提示和 LM 采样迭代生成候选架构,对它们进行训练并在任务数据集上评估适应度。
- 在轮次之间利用表现最好的架构对 LM 进行提示微调,以随时间改进交叉操作。
- 通过基于验证误差和模型大小的适应度函数对候选者进行评分(fitness = -model_size * validation_error)。
- 使用种子架构来初始化种群,并选择表现最佳的存活者进入下一代(精英策略)。
- 用提示微调对交叉 LM 进行多轮训练,从上下文示例中创建新的子代架构。
实验结果
研究问题
- RQ1放入进化循环中的代码预训练 LM 能否生成超越人类设计基线的新颖神经架构?
- RQ2EvoPrompting 是否通过提示微调和进化提示改善 LM 的上下文学习以进行架构设计?
- RQ3在轻量基准(MNIST-1D)与更复杂的图神经网络任务(CLRS)上,EvoPrompting 在准确率和模型规模方面的表现如何?
主要发现
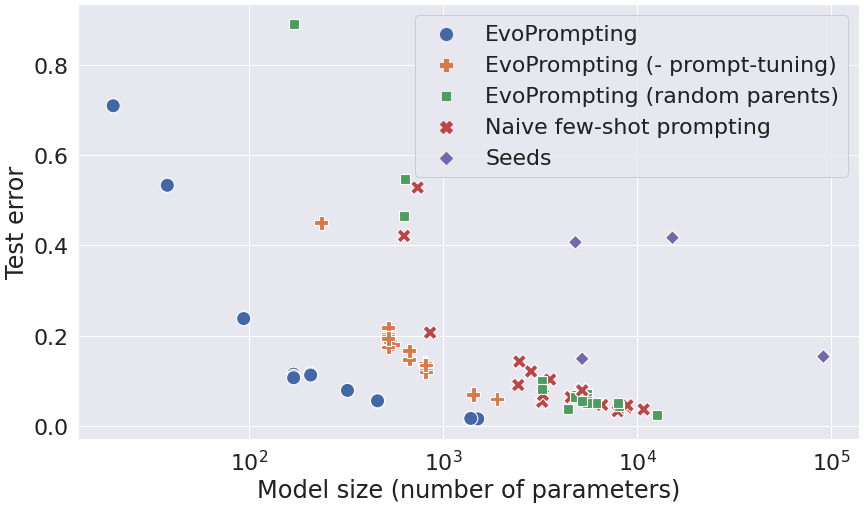
- EvoPrompting 在 MNIST-1D 上产生更小、性能更高的架构,超过了人类设计基线和直觉提示在准确性与规模上的表现。
- 在 MNIST-1D 上,EvoPrompting 实现了接近原点的帕累托前沿,表明更有利的准确性与规模权衡。
- 在 CLRS 中,EvoPrompting 发现了新型 GNN 架构,在多数任务中(30 个任务中有 21 个)优于 Triplet-GMPNN 基线。
- 提示微调与进化交叉交错是必不可少的;移除提示微调或使用随机父代会降低性能。
- 代码词汇表 LM 使在任意 Python 定义的架构上进行搜索成为可能,降低了对手工设计搜索空间的依赖。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。