[论文解读] Execution-based Code Generation using Deep Reinforcement Learning
PPOCoder 使用近端策略优化,对预训练代码模型在非可微执行反馈和基于结构的奖励下进行微调,以提高跨任务与跨语言的可编译性与功能正确性。
The utilization of programming language (PL) models, pre-trained on large-scale code corpora, as a means of automating software engineering processes has demonstrated considerable potential in streamlining various code generation tasks such as code completion, code translation, and program synthesis. However, current approaches mainly rely on supervised fine-tuning objectives borrowed from text generation, neglecting unique sequence-level characteristics of code, including but not limited to compilability as well as syntactic and functional correctness. To address this limitation, we propose PPOCoder, a new framework for code generation that synergistically combines pre-trained PL models with Proximal Policy Optimization (PPO) which is a widely used deep reinforcement learning technique. By utilizing non-differentiable feedback from code execution and structure alignment, PPOCoder seamlessly integrates external code-specific knowledge into the model optimization process. It's important to note that PPOCoder is a task-agnostic and model-agnostic framework that can be used across different code generation tasks and PLs. Extensive experiments on three code generation tasks demonstrate the effectiveness of our proposed approach compared to SOTA methods, achieving significant improvements in compilation success rates and functional correctness across different PLs.
研究动机与目标
- 通过引入执行和结构正确性来提升代码生成,超越面向 token 的目标。
- 提出一个任务与模型无关的 RL 框架(PPOCoder),利用不可微分的执行反馈。
- 在 KL 正则化的 PPO 目标中,整合编译信号、基于 AST 的句法匹配和基于 DFG 的语义匹配。
- 在代码补全、代码翻译,以及 NL2Code 任务中展示编译率与功能正确性的提升。
提出的方法
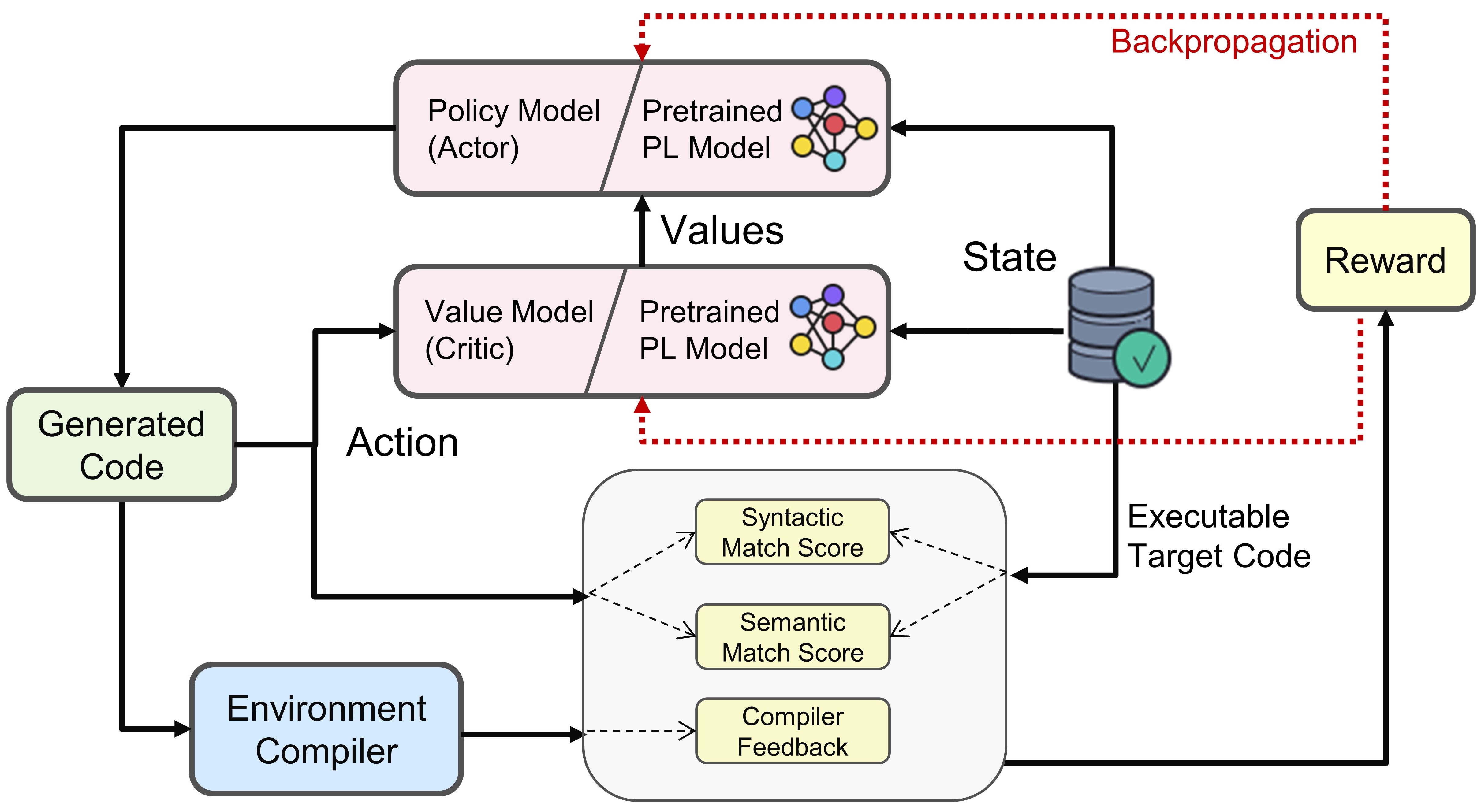
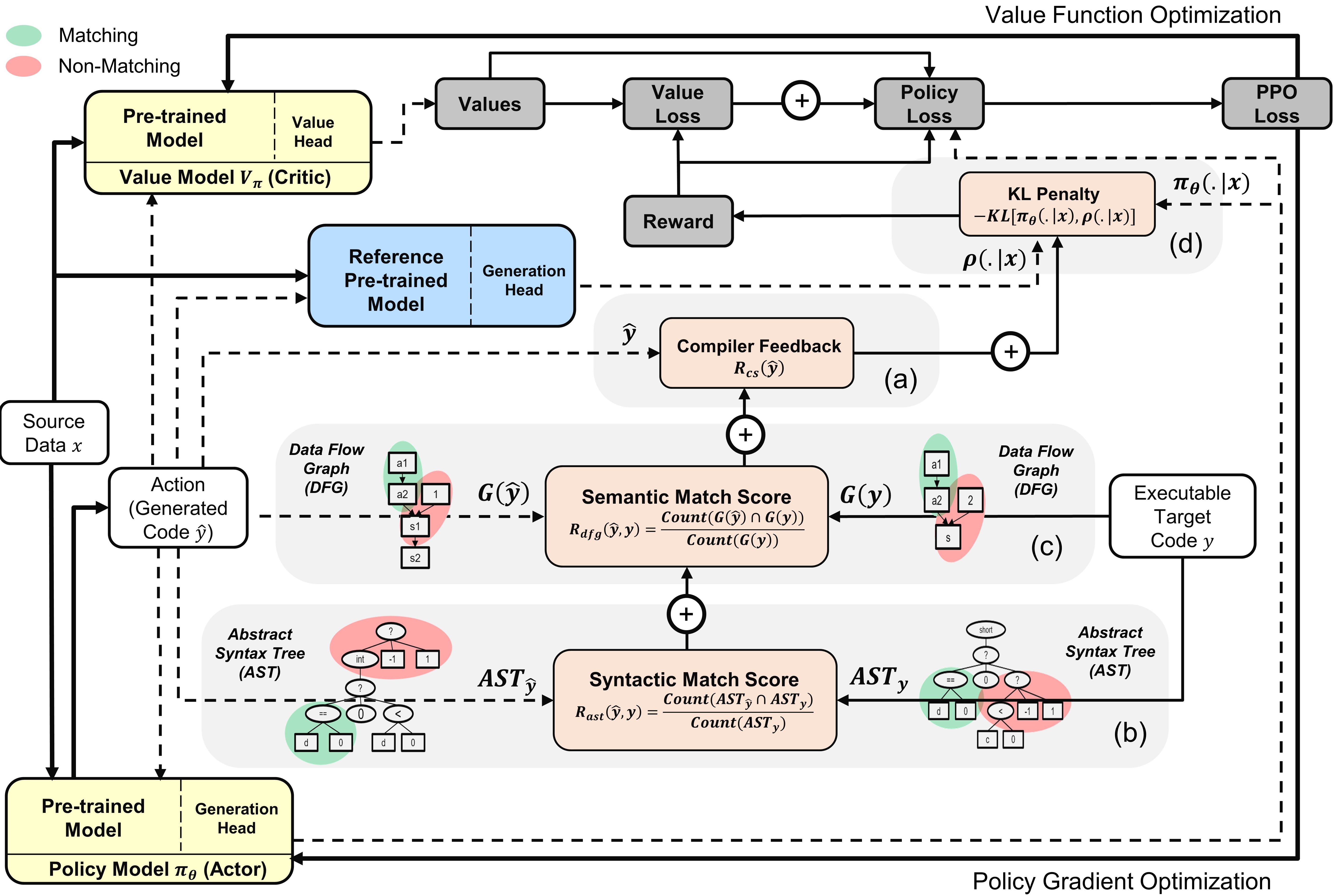
- 从目标任务的预训练代码模型初始化 actor/critic。
- 从当前策略中采样代码,并基于编译器反馈、AST 匹配、DFG 匹配以及 KL 发散项,计算一个综合的终局奖励。
- 使用 CPI 代理目标和价值头进行 PPO 优化,确保更新稳定且偏离最小。
- 奖励要素包括:编译信号(单元测试或句法正确性)、基于 AST 的句法匹配、基于 DFG 的语义匹配,以及 KL 惩罚。
- 通过 KL 发散项和基于裁剪的 PPO 更新,鼓励探索/利用的平衡。
实验结果
研究问题
- RQ1基于 PPO 的微调,结合不可微执行反馈,能否在多种编程语言中提升可编译性与功能正确性?
- RQ2编译信号、AST 结构匹配和 DFG 语义匹配如何共同提升代码生成质量?
- RQ3该方法在代码补全、代码翻译、NL 到代码等任务以及编程语言上是否鲁棒?
- RQ4引入 KL 发散惩罚是否能缓解记忆化、提升泛化?
主要发现
| Model | xMatch | Edit Sim | Comp Rate |
|---|---|---|---|
| BiLSTM | 20.74 | 55.32 | 36.34 |
| Transformer | 38.91 | 61.47 | 40.22 |
| GPT-2 | 40.13 | 63.02 | 43.26 |
| CodeGPT | 41.98 | 64.47 | 46.84 |
| CodeT5 (220M) | 42.61 | 68.54 | 52.14 |
| PPOCoder + CodeT5 (220M) | 42.63 | 69.22 | 97.68 |
- PPOCoder + CodeT5 将代码补全的编译率从 52.14% 提升至 97.68%。
- PPOCoder + CodeT5 在 xMatch(42.63)和编辑相似度(69.22)方面,分别优于 CodeT5 单独(42.61、68.54)。
- 在 XLCoST 的代码翻译任务中,PPOCoder + CodeT5 在多语言中获得更高的编译率,并在 Python 与 Java 等语言上取得显著提升,CodeBLEU 分数也具竞争力。
- 该框架在六种目标语言(C++、Java、Python、C#、PHP、C)上提升编译率,并在 CodeBLEU 分数上保持语义对齐。
- 消融研究表明,奖励组成部分(编译信号、AST/DFG 匹配、KL 惩罚)对性能提升与训练稳定性均有贡献。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。