[论文解读] Exploiting Diffusion Prior for Real-World Image Super-Resolution
本论文使用预训练的文本到图像扩散模型作为固定先验,并微调一个轻量级、具备时间感知的编码器,结合可控特征包裹模块与渐进聚合采样,以实现对扩散模型不重新训练的真实世界盲超分辨率。
We present a novel approach to leverage prior knowledge encapsulated in pre-trained text-to-image diffusion models for blind super-resolution (SR). Specifically, by employing our time-aware encoder, we can achieve promising restoration results without altering the pre-trained synthesis model, thereby preserving the generative prior and minimizing training cost. To remedy the loss of fidelity caused by the inherent stochasticity of diffusion models, we employ a controllable feature wrapping module that allows users to balance quality and fidelity by simply adjusting a scalar value during the inference process. Moreover, we develop a progressive aggregation sampling strategy to overcome the fixed-size constraints of pre-trained diffusion models, enabling adaptation to resolutions of any size. A comprehensive evaluation of our method using both synthetic and real-world benchmarks demonstrates its superiority over current state-of-the-art approaches. Code and models are available at https://github.com/IceClear/StableSR.
研究动机与目标
- 激发并开发一种盲超分辨率方法,在不重新训练预训练扩散模型的前提下,保持其生成先验。
- 提出一种轻量级时间感知编码器,用于在低分辨率输入下对固定的扩散模型进行条件化。
- 引入一个可控特征包裹模块,在重建过程中平衡保真度与真实感。
- 开发渐进聚合采样策略,以处理任意大小的输出并避免拼块引入的伪影。
- 在合成与真实世界的超分基准上,展示相对于现有方法的卓越性能。
提出的方法
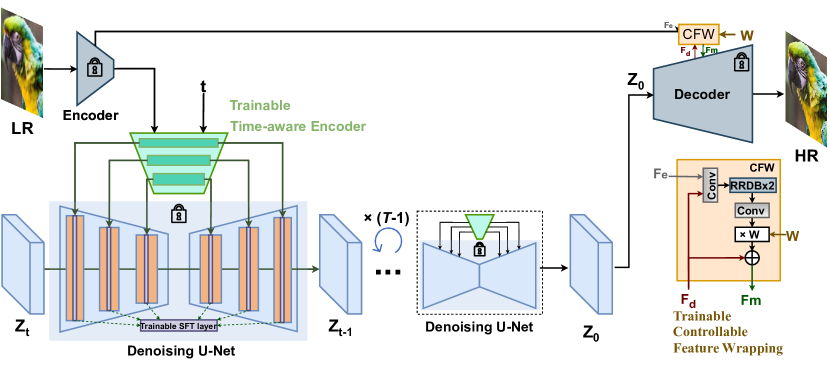
- 对固定的 Stable Diffusion 模型进行微调,附加一个轻量级的时间感知编码器,通过多尺度特征调制(SFT)实现对超分辨率的条件化。
- 引入时间感知引导,使条件强度在扩散步数中自适应调整,在早期迭代阶段实现更强的引导。
- 添加可控特征包裹(CFW)模块,通过可调权重 w 将编码器/解码器特征融合,权衡保真度与真实感。
- 应用颜色校正(像素域和小波基变体)以减轻扩散输出中的色偏。
- 在扩散迭代过程中使用渐进聚合采样策略,通过重叠补丁和高斯加权融合来处理任意分辨率。

实验结果
研究问题
- RQ1如何在不重新训练模型的情况下,利用预训练的扩散模型实现真实世界的盲超分辨率?
- RQ2需要哪些轻量级组件来在保持生成先验的同时,对固定的扩散先验进行低分辨率图像的条件化?
- RQ3在基于扩散的超分辨中,保真度与真实感的权衡是否可以被可控地管理?
- RQ4如何在基于扩散的超分辨中实现任意图像分辨率而不产生边界伪影?
- RQ5基于扩散先验的超分辨方法在合成与真实基准上是否优于现有的真实世界超分基线?
主要发现
| 数据集 | PSNR | SSIM | LPIPS | FID | CLIP-IQA | MUSIQ |
|---|---|---|---|---|---|---|
| DIV2K Valid | 24.62 | 0.5970 | 0.5276 | 49.49 | 0.3534 | 28.57 |
| RealSR | 27.30 | 0.7579 | 0.3570 | 0.3687 | 38.26 | |
| DRealSR | 30.19 | 0.8148 | 0.3938 | 0.3744 | 26.93 | |
| DPED-iphone | - | - | - | - | 0.4496 | 45.60 |
- StableSR 在合成和真实世界基准上的感知指标,如 FID、CLIP-IQA 和 MUSIQ,超越了现有最先进的超分方法。
- 时间感知引导通过在推理过程中自适应调节扩散条件强度来提升保真度和清晰度。
- 可控特征包裹提供了高保真结构与真实纹理之间的可调平衡,实现实用的保真度-真实感权衡(最优在 w≈0.5 时)。
- 渐进聚合采样实现了对分辨率大于 512x512 的稳定超分,而不会出现基于拼块的边界伪影。
- 颜色校正(像素域和小波基变体)降低色偏并提升视觉质量。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。