[论文解读] Exploring Parameter-Efficient Fine-Tuning Techniques for Code Generation with Large Language Models
该论文评估用于 Python 代码生成的 PEFT 技术(LoRA、IA3、Prompt tuning、Prefix tuning),并在资源受限下与 ICL 与完整微调进行比较,同时探索联合训练与量化(QLoRA)以降低内存使用。
Large language models (LLMs) demonstrate impressive capabilities to generate accurate code snippets given natural language intents in a zero-shot manner, i.e., without the need for specific fine-tuning. While prior studies have highlighted the advantages of fine-tuning LLMs, this process incurs high computational costs, making it impractical in resource-scarce environments, particularly for models with billions of parameters. To address these challenges, previous research explored in-context learning (ICL) and retrieval-augmented generation (RAG) as strategies to guide the LLM generative process with task-specific prompt examples. However, ICL and RAG introduce inconveniences, such as the need for designing contextually relevant prompts and the absence of learning task-specific parameters, thereby limiting downstream task performance. In this context, we foresee parameter-efficient fine-tuning (PEFT) as a promising approach to efficiently specialize LLMs to task-specific data while maintaining reasonable resource consumption. In this paper, we deliver a comprehensive study of PEFT techniques for LLMs in the context of automated code generation. Our comprehensive investigation of PEFT techniques for LLMs reveals their superiority and potential over ICL and RAG across a diverse set of LLMs and three representative Python code generation datasets: Conala, CodeAlpacaPy, and APPS. Furthermore, our study highlights the potential for tuning larger LLMs and significant reductions in memory usage by combining PEFT with quantization. Therefore, this study opens opportunities for broader applications of PEFT in software engineering scenarios. Our code is available at https://github.com/martin-wey/peft-llm-code/.
研究动机与目标
- 评估在 Python 代码生成任务中,经过 PEFT 调整的大语言模型与经过完全微调并具备 PEFT 的小模型相比的性能。
- 评估在代码相关任务中,PEFT 方法是否优于 In-Context Learning (ICL)。
- 探索在对两个数据集进行联合微调时,LoRA 的有效性。
- 研究通过将 LoRA 与量化相结合,在大型模型上进一步降低资源消耗。
提出的方法
- 比较四种 PEFT 技术(LoRA、IA3、Prompt tuning、Prefix tuning)在多个模型家族(CodeT5+、CodeGen、CodeGen2、CodeLlama)以及八个大型变体和三个小型变体上的表现。
- 在两个 Python 代码生成数据集(CoNaLa、CodeAlpacaPy)上进行评估,以避免 HumanEval 偏差。
- 在 24 GB GPU 限制下,与 In-Context Learning 以及对较小模型的全量微调进行基准对比。
- 测试在两个数据集上联合训练的 LoRA 适配器,并与单数据集的 LoRA 适配器进行比较。
- 研究 QLoRA 以降低内存占用,并在资源有限的情况下实现对高达 34B 参数的大型模型的微调。
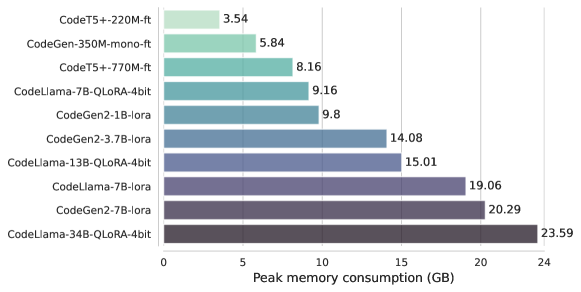
实验结果
研究问题
- RQ1RQ1:在 24 GB GPU 内存下,经过 PEFT 调整的 LLM 与对小模型进行全量微调并应用 PEFT 的情况相比,在代码生成任务上表现如何?
- RQ2RQ2:在代码任务中,PEFT 技术是否比 ICL 更具潜力?
- RQ3RQ3:在对两个数据集进行联合微调时,LoRA 的表现如何?
- RQ4RQ4:将 LoRA 与量化结合是否能够在对较大模型进行微调时进一步降低资源使用?
主要发现
- LoRA、IA3 以及 Prompt-tuning 调整的 LLM(可训练参数只有几百万)在性能上优于使用数亿参数进行完全微调的小型模型。
- LoRA 通常在 PEFT 方法中具有最高的有效性,且能够在小模型上超过全量微调。
- 与 ICL 相比,LoRA 在 CoNaLa 和 CodeAlpacaPy 的所有模型上都显著提升性能。
- 在两个数据集上联合训练的单一 LoRA 适配器达到的效果与针对单一数据集的 LoRA 适配器相似。
- QLoRA 大幅降低内存使用,使微调所需内存约为 LoRA 的一半,并支持在低于 24 GB 的资源下对 CodeLlama-34B 进行微调。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。