[论文解读] Extract, Define, Canonicalize: An LLM-based Framework for Knowledge Graph Construction
EDC 是一个三阶段的基于大模型驱动的知识图谱构建框架,先以开放信息提取开始,然后定义模式,最后将三元组规范化为预定义模式或自生成模式,增强的检索增强的模式检索器提升提取质量。
In this work, we are interested in automated methods for knowledge graph creation (KGC) from input text. Progress on large language models (LLMs) has prompted a series of recent works applying them to KGC, e.g., via zero/few-shot prompting. Despite successes on small domain-specific datasets, these models face difficulties scaling up to text common in many real-world applications. A principal issue is that, in prior methods, the KG schema has to be included in the LLM prompt to generate valid triplets; larger and more complex schemas easily exceed the LLMs' context window length. Furthermore, there are scenarios where a fixed pre-defined schema is not available and we would like the method to construct a high-quality KG with a succinct self-generated schema. To address these problems, we propose a three-phase framework named Extract-Define-Canonicalize (EDC): open information extraction followed by schema definition and post-hoc canonicalization. EDC is flexible in that it can be applied to settings where a pre-defined target schema is available and when it is not; in the latter case, it constructs a schema automatically and applies self-canonicalization. To further improve performance, we introduce a trained component that retrieves schema elements relevant to the input text; this improves the LLMs' extraction performance in a retrieval-augmented generation-like manner. We demonstrate on three KGC benchmarks that EDC is able to extract high-quality triplets without any parameter tuning and with significantly larger schemas compared to prior works. Code for EDC is available at https://github.com/clear-nus/edc.
研究动机与目标
- 在不依赖小型预定义模式的情况下,使用大模型从通用文本中推动自动化知识图谱构建(KGC)。
- 将KGC分解为三个阶段——开放信息提取、模式定义和模式规范化,以降低提示上下文窗口的约束。
- 同时启用目标对齐(预定义的大型模式)和自我规范化(自动创建的模式)设置。
- 引入一个经过训练的模式检索器,以检索与输入文本相关的模式组件并提升抽取质量。
- 在三个基准上展示EDC和EDC+R,取得有利结果且在提取阶段未进行参数调优。
提出的方法
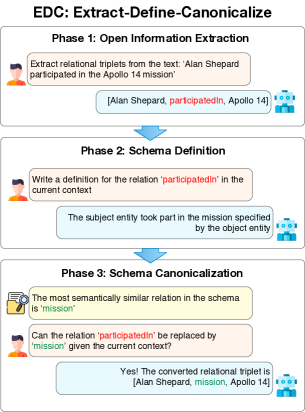
- 三阶段的EDC框架: (i) 开放信息提取,在没有模式约束的情况下生成三元组,(ii) 模式定义,为诱导的模式组件生成自然语言定义,(iii) 模式规范化,将三元组映射到规范形式,可以通过目标对齐或自我规范化实现。
- 使用LLMs通过解释来证明抽取的合理性,并推导用于规范化的定义。
- 将规范化表示为对嵌入的模式定义进行向量相似性搜索,随后进行LLM驱动的可行转换验证。
- 细化(EDC+R)在提取阶段添加检索增强的提示,将来自前几轮的候选实体/关系合并,并使用经过训练的模式检索器来引导OIE。
- 模式检索器是一个对E5-mistral-7b-instruct进行微调的模型,使用文本-定义关系对进行训练,将文本和模式投射到一个共享向量空间以进行相关性评分。
- 迭代细化至最多再进行一次额外迭代,利用提示提升抽取质量。
实验结果
研究问题
- RQ1基于LLM的三阶段管线在没有预定义的小型模式的情况下是否也能产生高质量的KGC?
- RQ2事后规范化在对齐到现有模式与自生成模式时,如何影响三元组的质量与冗余?
- RQ3检索增强的模式检索器是否在具有大型或在发展中的模式的数据集上提升抽取性能?
- RQ4在具有大型模式类型的真实世界KGC中,使用目标对齐与自我规范化各自有哪些权衡?
主要发现
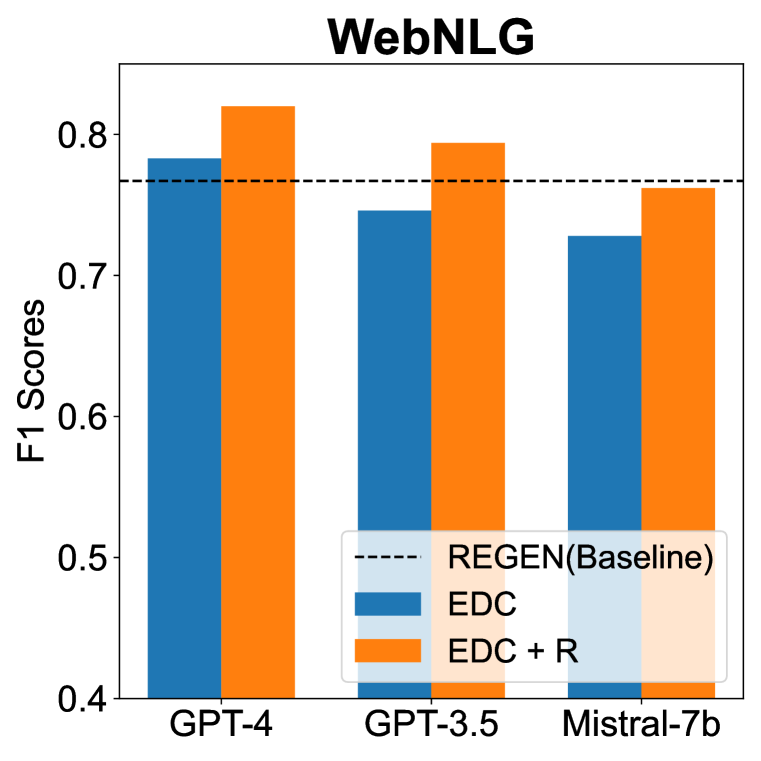
- EDC在目标对齐和自我规范化方面,在三个KGC基准上超越了最先进的基线且未进行参数调优。
- 单次细化迭代(EDC+R)在所测试的LLMs中持续提升性能。
- 模式检索器显著提升性能,使得可以捕捉到更细粒度的关系(如校园与地点之分),这是OIE阶段可能遗漏的。
- 自我规范化在人工评估中产生简洁、冗余更少的模式,且精度高于CESI基线。
- 实际评估显示开放KG三元组是正确的,但相对详尽的参考集可能过于扩张,突出了数据集标注差异。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。