[论文解读] Facial Affect Recognition based on Transformer Encoder and Audiovisual Fusion for the ABAW5 Challenge
该论文提出基于 Transformer 编码器的多模态框架,使用仿射模块融合音频与视觉特征,覆盖四个 ABAW5 子挑战,在 VA、Expr、AU、ERI 任务上取得了最先进的结果。
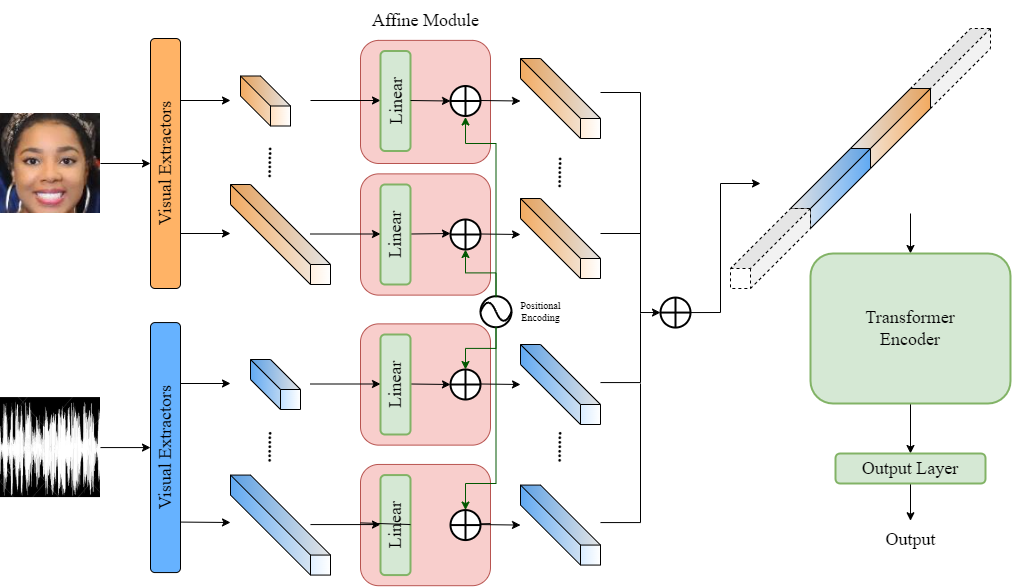
In this paper, we present our solutions for the 5th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW), which includes four sub-challenges of Valence-Arousal (VA) Estimation, Expression (Expr) Classification, Action Unit (AU) Detection and Emotional Reaction Intensity (ERI) Estimation. The 5th ABAW competition focuses on facial affect recognition utilizing different modalities and datasets. In our work, we extract powerful audio and visual features using a large number of sota models. These features are fused by Transformer Encoder and TEMMA. Besides, to avoid the possible impact of large dimensional differences between various features, we design an Affine Module to align different features to the same dimension. Extensive experiments demonstrate that the superiority of the proposed method. For the VA Estimation sub-challenge, our method obtains the mean Concordance Correlation Coefficient (CCC) of 0.6066. For the Expression Classification sub-challenge, the average F1 Score is 0.4055. For the AU Detection sub-challenge, the average F1 Score is 0.5296. For the Emotional Reaction Intensity Estimation sub-challenge, the average pearson's correlations coefficient on the validation set is 0.3968. All of the results of four sub-challenges outperform the baseline with a large margin.
研究动机与目标
- 在野外场景中推动对多任务(VA、Expr、AU、ERI)的鲁棒人脸情感识别。
- 利用来自最先进模型的多样化音频与视觉特征以提升性能。
- 引入一个 Affine 模块在融合前对齐异构特征维度。
- 应用 Transformer Encoder(ERI 使用 TEMMA)来建模时间动态。
- 在四个 ABAW5 子挑战上展示出相对于基线的优越性能。
提出的方法
- 使用多种音频编码器(IS09、VGGish、eGeMAPS、DeepSpectrum、CNN14)提取音频特征。
- 从多种架构提取视觉特征(EAC、ResNet18、POSTER、POSTER2、FAU、OPENFace FAU)。
- 使用 Affine 模块对齐异构特征维度并添加位置编码。
- 拼接仿射对齐后的特征并使用 Transformer Encoder(ERI 使用 TEMMA)建模时间关系。
- 使用任务特定的输出层解码预测,并以适合任务的损失函数进行优化(VA/ERI 的 MSE,Expr 的 CE,AU 的加权非对称损失)。
- 在 RAF-DB 和 AffectNet 上对视觉特征提取器进行预训练;在 ABAW5 数据集(Aff-Wild2 变体和 Hume-Reaction)上进行训练与评估。
实验结果
研究问题
- RQ1通过 Transformer 基编码器融合的多模态音视频特征是否可以提升所有 ABAW5 子挑战的性能?
- RQ2使用 Affine 模块对齐异构特征维度对融合效果有何影响?
- RQ3与标准 Transformer 编码器相比,基于 TEMMA 的时间建模是否为 ERI 估计带来增益?
- RQ4哪些特征组合在 VA、Expr、AU 和 ERI 任务上能获得最佳验证性能?
主要发现
| Features | VA | Arousal | Mean |
|---|---|---|---|
| Baseline | 0.24 | 0.20 | 0.22 |
| EAC | 0.4479 | 0.5878 | 0.5179 |
| POSTER | 0.3920 | 0.6317 | 0.5119 |
| ResNet18 | 0.4762 | 0.5671 | 0.5217 |
| POSTER2 | 0.5374 | 0.6297 | 0.5836 |
| ResNet18+VGGish | 0.4742 | 0.6220 | 0.5481 |
| ResNet18+POSTER2 | 0.5515 | 0.6429 | 0.5972 |
| ResNet18+POSTER2+FAU | 0.4868 | 0.6301 | 0.5585 |
| POSTER2+POSTER+VGGish | 0.5003 | 0.6946 | 0.5975 |
| EAC+ResNet18+POSTER2+VGGish | 0.5542 | 0.6590 | 0.6066 |
- 对于 VA 估计,最佳单一特征是 POSTER2(Mean=0.5836),最佳多特征组合(ResNet18+POSTER2+FAU)达到 Mean=0.5585, combining EAC、ResNet18、POSTER2、VGGish 时的最佳整体 Mean 为 0.6066。
- VA 验证均值 CCC 为 0.6066,显示出对基线的显著改进。
- Expr 分类在仅使用 POSTER2 时达到最佳 F1 分数(0.4055),并通过组合 ResNet18 与 POSTER2 改善(0.3957–0.4055 区间)。
- AU 检测在使用 POSTER2 和 FAU 特征时达到更高的 F1 分数(0.5296),优于基线,表明多模态融合有效。
- ERI 估计在将 ResNet18 与 DeepSpectrum 结合时显示最佳 PCC(0.3968),表明音视频线索具有互补性。
- 在 ABAW5 中,四个子挑战都比基线有显著提升。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。