[论文解读] Fairness of ChatGPT and the Role Of Explainable-Guided Prompts
本文研究使用 OpenAI 的 GPT 结合提示工程和领域知识进行信用风险评估,显示在数据远少于传统 ML 的情况下仍具竞争力,并就性别公平性提供洞见。
Our research investigates the potential of Large-scale Language Models (LLMs), specifically OpenAI's GPT, in credit risk assessment-a binary classification task. Our findings suggest that LLMs, when directed by judiciously designed prompts and supplemented with domain-specific knowledge, can parallel the performance of traditional Machine Learning (ML) models. Intriguingly, they achieve this with significantly less data-40 times less, utilizing merely 20 data points compared to the ML's 800. LLMs particularly excel in minimizing false positives and enhancing fairness, both being vital aspects of risk analysis. While our results did not surpass those of classical ML models, they underscore the potential of LLMs in analogous tasks, laying a groundwork for future explorations into harnessing the capabilities of LLMs in diverse ML tasks.
研究动机与目标
- 调查像 ChatGPT 这样的大型语言模型在数据有限的情况下是否能够执行信用风险分类。
- 评估提示设计和领域知识如何影响预测准确性。
- 使用自助法(bootstrap)基于真正阳性率(TPR)的比较与统计检验来评估性别公平性。
- 提供将领域知识和提示策略整合以提升大语言模型辅助的机器学习任务的指南。
提出的方法
- 使用 ChatGPT-3.5-Turbo 将信用风险任务转换为基于对话的预测问题。
- 设计包含任务指令、上下文示例、属性描述、领域知识和问题表述的多部分提示。
- 通过 ML 派生的特征重要性(MLFI)及其有序变体(MLFI-ord)融入领域知识。
- 在德国信用数据集上使用 5 折交叉验证,对经典 ML 模型和基于 OpenAI 的模型进行性能评估。
- 使用自助抽样(1000 次重采样)通过真正例率差异评估性别公平性。
- 比较各模型的准确性、精确率、召回率、F1 分数以及假阳性/假阴性的成本。
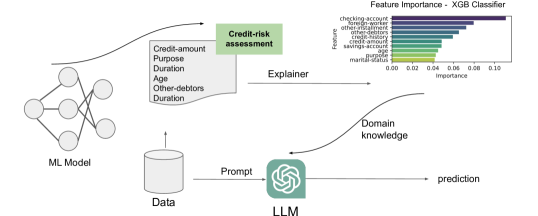
实验结果
研究问题
- RQ1在数据显著更少的情况下,结合精心设计的提示和领域知识,ChatGPT 是否能够实现与经典 ML 相媲美的信用风险预测?
- RQ2提示设计(包括领域知识和特征排序)如何影响基于 OpenAI 的预测的准确性和公平性?
- RQ3在信用风险评估中,基于 OpenAI 的模型是否表现出与传统 ML 模型不同的性别公平性特征?
- RQ4在将提示工程和领域知识整合以改进带有大语言模型的机器学习任务时,会出现哪些实用指南?
主要发现
| 模型 | DK 类型 | ML 模型 | 准确率 | 召回 | F1 | 假阳性成本 | 假阴性成本 |
|---|---|---|---|---|---|---|---|
| RF | - | - | 0.8153 | 0.9078 | 0.8591 | 145.0 | 13.0 |
| LR | - | - | 0.7368 | 0.8936 | 0.8077 | 225.0 | 15.0 |
| MLP | - | - | 0.7654 | 0.8794 | 0.8185 | 190.0 | 17.0 |
| KNN | - | - | 0.7707 | 0.8582 | 0.8121 | 180.0 | 20.0 |
| XGB | - | - | 0.8077 | 0.8936 | 0.8485 | 150.0 | 15.0 |
| AdaBoost | - | - | 0.7875 | 0.8936 | 0.8372 | 170.0 | 15.0 |
| random | - | - | 0.7625 | 0.4326 | 0.5520 | 95.0 | 80.0 |
| Avg. | - | - | 0.7792 | 0.8822 | 0.8302 | 172.5 | 15.6 |
| prompt-0 | N/A | - | 0.7625 | 0.4326 | 0.5520 | 95.0 | 80.0 |
| prompt-1 | MLFI | XGB | 0.7083 | 0.7234 | 0.7158 | 210.0 | 39.0 |
| prompt-2 | MLFI-ord | XGB | 0.6842 | 0.5532 | 0.6118 | 180.0 | 63.0 |
| prompt-3 | MLFI | RF | 0.7206 | 0.6950 | 0.7076 | 190.0 | 43.0 |
| prompt-4 | MLFI-ord | RF | 0.7087 | 0.5177 | 0.5984 | 150.0 | 68.0 |
| prompt-5 | MLFI | Ada | 0.7305 | 0.7305 | 0.7305 | 190.0 | 38.0 |
| prompt-6 | MLFI-ord | Ada | 0.7404 | 0.5461 | 0.6286 | 135.0 | 64.0 |
| prompt-7 | MLFI | LR | 0.7154 | 0.6596 | 0.6863 | 185.0 | 48.0 |
| prompt-8 | MLFI-ord | LR | 0.6957 | 0.4539 | 0.5494 | 140.0 | 77.0 |
| prompt-9 | MLFI | ensemble | 0.7209 | 0.6596 | 0.6889 | 180.0 | 48.0 |
| prompt-10 | MLFI-ord | ensemble | 0.7037 | 0.5390 | 0.6104 | 160.0 | 65.0 |
- 基于 OpenAI 的模型仅用 20 个训练样本就取得与经典 ML 模型 800 个样本相比具有竞争力的结果。
- 在 OpenAI 基于配置中,带有 MLFI 提示的 AdaBoost 产生较高的精确率、召回率和 F1(0.7305)。
- 在平均准确率等指标上,经典 ML 模型优于基于 OpenAI 的模型(准确率 0.7792 vs 0.7129;召回率 0.8822 vs 0.6078;F1 0.8302 vs 0.6528)。
- OpenAI 模型的假阳性成本低于经典 ML 模型,表明在放贷决策上更谨慎。
- 公平性分析显示,某些提示(如 Prompt-5、Prompt-7)接近非显著的性别差异,而其他提示则存在显著差异;经典模型通常拒绝公平性原假设(显著差异)。
- 提示有时能够在结果上促进公平,凸显了基于提示的公平性考量在 LLM 辅助的 ML 任务中的潜力。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。