[论文解读] FeatUp: A Model-Agnostic Framework for Features at Any Resolution
FeatUp 将深度特征放大到更高的空间分辨率,同时不改变语义,通过快速的基于 JBU 的上采样器或隐式的逐图像模型,并由多视角一致性引导。
Deep features are a cornerstone of computer vision research, capturing image semantics and enabling the community to solve downstream tasks even in the zero- or few-shot regime. However, these features often lack the spatial resolution to directly perform dense prediction tasks like segmentation and depth prediction because models aggressively pool information over large areas. In this work, we introduce FeatUp, a task- and model-agnostic framework to restore lost spatial information in deep features. We introduce two variants of FeatUp: one that guides features with high-resolution signal in a single forward pass, and one that fits an implicit model to a single image to reconstruct features at any resolution. Both approaches use a multi-view consistency loss with deep analogies to NeRFs. Our features retain their original semantics and can be swapped into existing applications to yield resolution and performance gains even without re-training. We show that FeatUp significantly outperforms other feature upsampling and image super-resolution approaches in class activation map generation, transfer learning for segmentation and depth prediction, and end-to-end training for semantic segmentation.
研究动机与目标
- 动机:在不重新训练或改变语义的情况下,找回深度特征表示中丢失的空间分辨率。
- 提出 FeatUp 作为一个框架,通过强化多视图一致性来从低分辨率视图重建高分辨率特征。
- 给出两个变体:一个是快速前馈的基于 JBU 的上采样器,另一个是逐图像的隐式上采样器。
- 展示 FeatUp 在下游任务上的改进,如语义分割、深度估计和 CAM 解释。
提出的方法
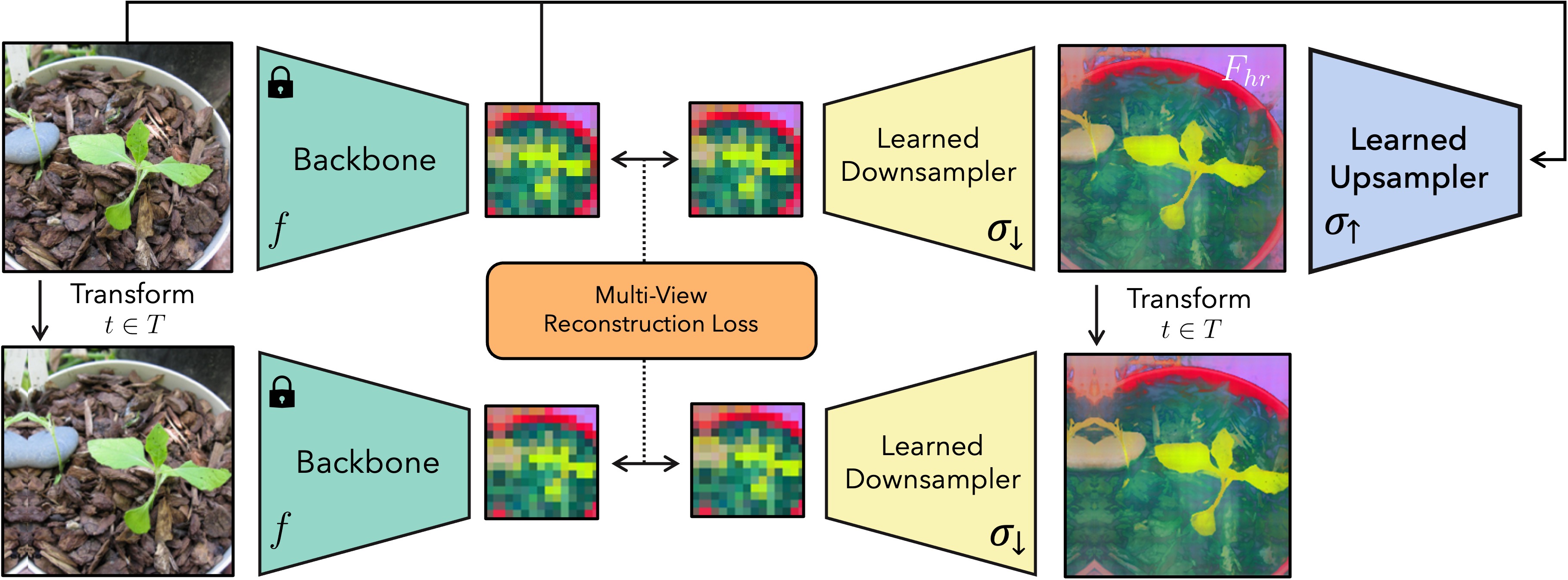
- 通过跨抖动输入变换(填充、缩放、翻转)实现多视图一致性来上采样深度特征。
- 提供两种上采样架构:/i) 联合双边上采样器(JBU),作为快速、有引导的前向模块;/ii) 隐式 FeatUp,对单张图像拟合一个 MLP,以输出任意分辨率。
- 引入一个可学习的下采样器(简单模糊或基于注意力的)将高分辨率特征映射到低分辨率视图。
- 使用多视图重建损失,将下采样后的高分辨率特征与低分辨率主干输出对齐,并带有自适应不确定性项。
- 提供 CUDA 加速的 JBU 实现以提高效率,及在隐式模型中可选的傅里叶特征以加速收敛。
- 对隐式特征幅度应用较小的全变分先验以稳定。
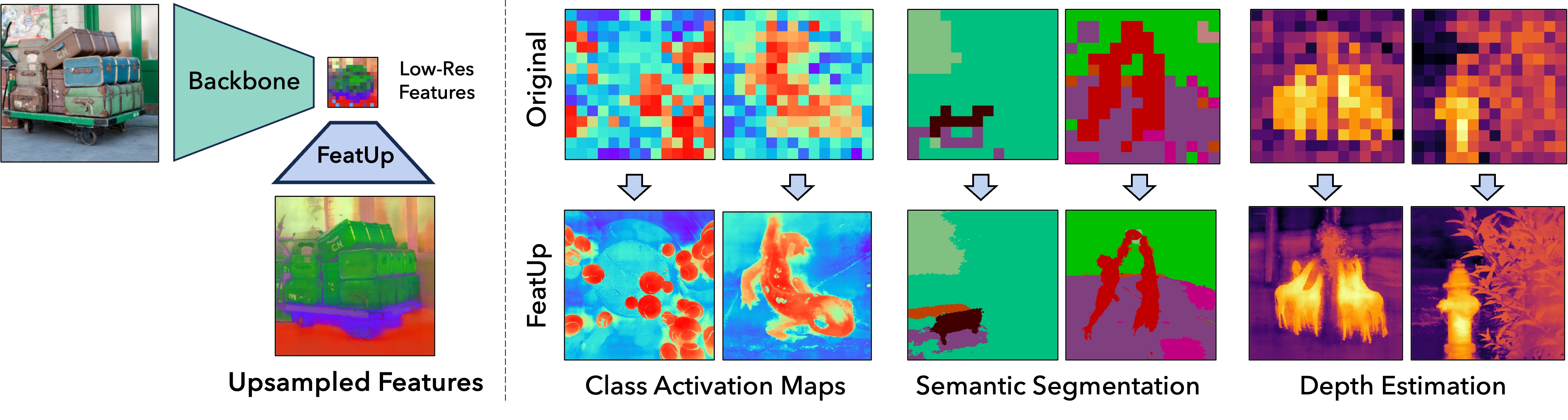
实验结果
研究问题
- RQ1在不改变其语义或重新训练主干网络的前提下,深度特征的空间分辨率是否能够显著提高?
- RQ2在图像抖动上的多视图一致性是否提供了用于高分辨率特征重建的鲁棒监督信号?
- RQ3在不同主干和任务中,快速的 JBU 基于上采样与隐式逐图像上采样方法在质量、速度和内存占用方面的比较如何?
- RQ4FeatUp 特征能否作为直接替换以提升下游密集预测和模型可解释性?
- RQ5FeatUp 派生的特征是否在 CAM 质量上带来可衡量的提升以改善模型可解释性?
主要发现
| 方法 | CAM 评分 A.D.↓ | CAM 评分 A.I.↑ | 语义分割 mIoU↑ | 语义分割 准确度↑ | 深度 RMSE↓ | 深度 δ>1.25↑ |
|---|---|---|---|---|---|---|
| Low-res | 10.69 | 4.81 | 65.17 | 40.65 | 1.25 | 0.894 |
| Bilinear | 10.24 | 4.91 | 66.95 | 42.40 | 1.19 | 0.910 |
| Resize-conv | 11.02 | 4.95 | 67.72 | 42.95 | 1.14 | 0.917 |
| DIP | 10.57 | 5.16 | 63.78 | 39.86 | 1.19 | 0.907 |
| Strided | 11.48 | 4.97 | 64.44 | 40.54 | 2.62 | 0.900 |
| Large image | 13.66 | 3.95 | 58.98 | 36.44 | 2.33 | 0.896 |
| CARAFE | 10.24 | 4.96 | 67.10 | 42.39 | 1.09 | 0.920 |
| SAPA | 10.62 | 4.85 | 65.69 | 41.17 | 1.19 | 0.917 |
| FeatUp (JBU) | 9.83 | 5.24 | 68.77 | 43.41 | 1.09 | 0.938 |
| FeatUp (Implicit) | 8.84 | 5.60 | 71.58 | 47.37 | 1.04 | 0.927 |
- FeatUp 在 CAM 可信度、语义分割和深度估计等方面,始终优于基线上采样方法(双线性、resize-conv、DIP 等)。
- FeatUp 的两种变体(JBU 和隐式)都提供更高质量的高分辨率特征,其中隐式变体在若干指标上带来最强的下游改进。
- 在迁移学习实验中,FeatUp 特征提升了语义分割的线性探头表现(mIoU)和深度估计的 RMSE、delta>1.25。
- FeatUp 上采样可以作为端到端分割模型的直接替换,带来更好的平均 IoU、平均精度和像素准确度,且 FLOPs/参数具有竞争力。
- CUDA 加速的 JBU 实现相较于天真的实现可实现约 10 倍以上加速并显著降低内存占用。
- 隐式 FeatUp 受益于傅里叶颜色特征,使收敛更快并捕捉到更高频细节。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。