[论文解读] FeCAM: Exploiting the Heterogeneity of Class Distributions in Exemplar-Free Continual Learning
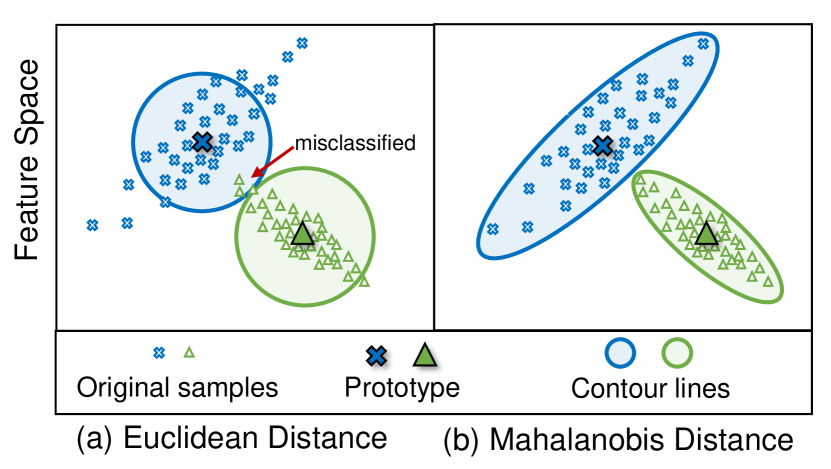
FeCAM 引入一个 Bayesian 分类器,该分类器使用 class-specific covariance (Mahalanobis distance) 来处理 exemplar-free continual learning 中的异质特征分布,在 many-shot 和 few-shot CIL 以及 domain-incremental 任务中,相对于基于 Euclidean 的原型方法,性能得到提升。
Exemplar-free class-incremental learning (CIL) poses several challenges since it prohibits the rehearsal of data from previous tasks and thus suffers from catastrophic forgetting. Recent approaches to incrementally learning the classifier by freezing the feature extractor after the first task have gained much attention. In this paper, we explore prototypical networks for CIL, which generate new class prototypes using the frozen feature extractor and classify the features based on the Euclidean distance to the prototypes. In an analysis of the feature distributions of classes, we show that classification based on Euclidean metrics is successful for jointly trained features. However, when learning from non-stationary data, we observe that the Euclidean metric is suboptimal and that feature distributions are heterogeneous. To address this challenge, we revisit the anisotropic Mahalanobis distance for CIL. In addition, we empirically show that modeling the feature covariance relations is better than previous attempts at sampling features from normal distributions and training a linear classifier. Unlike existing methods, our approach generalizes to both many- and few-shot CIL settings, as well as to domain-incremental settings. Interestingly, without updating the backbone network, our method obtains state-of-the-art results on several standard continual learning benchmarks. Code is available at https://github.com/dipamgoswami/FeCAM.
研究动机与目标
- 探究类别分布中的异质性如何影响 exemplar-free CIL 的性能。
- 评估使用带有 class-specific covariances 的各向异性 (Mahalanobis) 距离是否优于 Euclidean NCM 分类器。
- 开发一个协方差感知的 FeCAM 分类器,在 backbone 冻结和预训练特征下仍保持有效。
- 展示 FeCAM 在 many-shot、few-shot 和 domain-incremental 连续学习场景中的适用性。
提出的方法
- 使用带冻结 backbone 的原型网络来形成类别原型。
- 采用各向异性 Mahalanobis 距离 (FeCAM) 将特征与类别原型进行比较。
- 计算并归一化每个类别的协方差矩阵;应用协方差收缩以确保可逆。
- 在协方差估计之前,应用 Tukey 的 ladder 变换来稳定特征分布。
- 进行相关性归一化,使协方差矩阵在不同类别和任务之间具有可比性。
- 论证并验证具备类协方差的Bayes 分类器能够产生非线性、比从 Gaussian 样本训练得到的线性分类器更优的决策边界。
![Figure 1 : Illustration of feature representations in CIL settings. In Joint Training (a), deep neural networks learn good isotropic spherical representations [ 17 ] and thus the Euclidean metric can be used effectively. However, it is challenging to learn isotropic representations of both old and n](https://ar5iv.labs.arxiv.org/html/2309.14062/assets/x1.png)
实验结果
研究问题
- RQ1在 exemplar-free CIL 中,特征分布的 episodic 异质性是否会降低 Euclidean NCM 的性能,尤其是对于新类?
- RQ2具有 per-class covariances 的协方差感知 Mahalanobis 距离是否能在 exemplar-free CIL 中优于传统的 Euclidean 距离?
- RQ3Covariance normalization、shrinkage 和 Tukey 转换是否是 FeCAM 性能提升的关键组成部分?
- RQ4FeCAM 是否在 many-shot、few-shot 和 domain-incremental 连续学习基准上无需更新 backbone 就能泛化?
主要发现
| CIL Method | CIFAR-100 (T=5) Avg Acc | CIFAR-100 (T=10) Avg Acc | CIFAR-100 (T=20) Avg Acc | TinyImageNet (T=5) Avg Acc | TinyImageNet (T=10) Avg Acc | TinyImageNet (T=20) Avg Acc | ImageNet-Subset (T=5) Avg Acc | ImageNet-Subset (T=10) Avg Acc | ImageNet-Subset (T=20) Avg Acc |
|---|---|---|---|---|---|---|---|---|---|
| EWC | 24.5 | 21.2 | 15.9 | 18.8 | 15.8 | 12.4 | - | 20.4 | - |
| LwF-MC | - | - | - | - | - | - | - | - | - |
| DeeSIL | 60.0 | 50.6 | 38.1 | 49.8 | 43.9 | 34.1 | 67.9 | 60.1 | 50.5 |
| MUC | 49.4 | 30.2 | 21.3 | 32.6 | 26.6 | 21.9 | - | - | - |
| SDC | 56.8 | 57.0 | 58.9 | - | - | - | - | - | - |
| PASS | 63.5 | 61.8 | 58.1 | 49.6 | 47.3 | 42.1 | 64.4 | 61.8 | 51.3 |
| IL2A | 66.0 | 60.3 | 57.9 | 47.3 | 44.7 | 40.0 | - | - | - |
| SSRE | 65.9 | 65.0 | 61.7 | 50.4 | 48.9 | 48.2 | - | - | - |
| FeTrIL* | 67.6 | 66.6 | 63.5 | 55.4 | 54.3 | 53.0 | 73.1 | 71.9 | 69.1 |
| Eucl-NCM | 64.8 | 64.6 | 61.5 | 54.1 | 53.8 | 53.6 | 72.2 | 72.0 | 68.4 |
| FeCAM (Σ^{1:t}) | 68.8 | 68.6 | 67.4 | 56.0 | 55.7 | 55.5 | 75.8 | 75.6 | 73.5 |
| FeCAM (Σ_y) | 70.9 | 70.8 | 69.4 | 59.6 | 59.4 | 59.3 | 78.3 | 78.2 | 75.1 |
- FeCAM with a common covariance matrix (Σ^{1:t}) already surpasses prior exemplar-free CIL methods across CIFAR-100, TinyImageNet, and ImageNet-Subset.
- Using per-class covariance matrices (Σ_y) further improves average incremental accuracy, outperforming the common-covariance variant.
- FeCAM with per-class covariances achieves higher end-task accuracy and maintains strong performance across all tasks, including domain-incremental CoRe50.
- A Bayes classifier leveraging covariance relations yields substantially better accuracy than methods that sample Gaussian features and train a linear classifier.
- Covariance normalization (Eq. 7) and covariance shrinkage (Eq. 8) are crucial for handling variance shifts between old and new classes and ensuring invertibility.
- FeCAM scales well to pretrained backbones (ViT) and achieves state-of-the-art results on several benchmarks without backbone updates.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。