[论文解读] FedMKT: Federated Mutual Knowledge Transfer for Large and Small Language Models
FedMKT 提出一个联邦、互相知识转移框架,在服务端 LLM 与多客户端 SLMs 间,进行 token 对齐和选择性蒸馏,以共同提升服务器和客户端模型。
Recent research in federated large language models (LLMs) has primarily focused on enabling clients to fine-tune their locally deployed homogeneous LLMs collaboratively or on transferring knowledge from server-based LLMs to small language models (SLMs) at downstream clients. However, a significant gap remains in the simultaneous mutual enhancement of both the server's LLM and clients' SLMs. To bridge this gap, we propose FedMKT, a parameter-efficient federated mutual knowledge transfer framework for large and small language models. This framework is designed to adaptively transfer knowledge from the server's LLM to clients' SLMs while concurrently enriching the LLM with clients' unique domain insights. We facilitate token alignment using minimum edit distance (MinED) and then selective mutual knowledge transfer between client-side SLMs and a server-side LLM, aiming to collectively enhance their performance. Through extensive experiments across three distinct scenarios, we evaluate the effectiveness of FedMKT using various public LLMs and SLMs on a range of NLP text generation tasks. Empirical results demonstrate that FedMKT simultaneously boosts the performance of both LLMs and SLMs.
研究动机与目标
- 通过实现互相知识转移,弥合服务器端 LLMs 与客户端 SLMs 之间的差距。
- 开发一种使用 LoRA 适配器的参数高效方法,以降低通信和计算成本。
- 通过 token 对齐和选择性知识转移解决模型异质性,确保双方性能提升。
- 在多种 NLP 任务上,使用公开的 LLMs/SLMs,在异质、同质、以及一对一设置下评估 FedMKT。
提出的方法
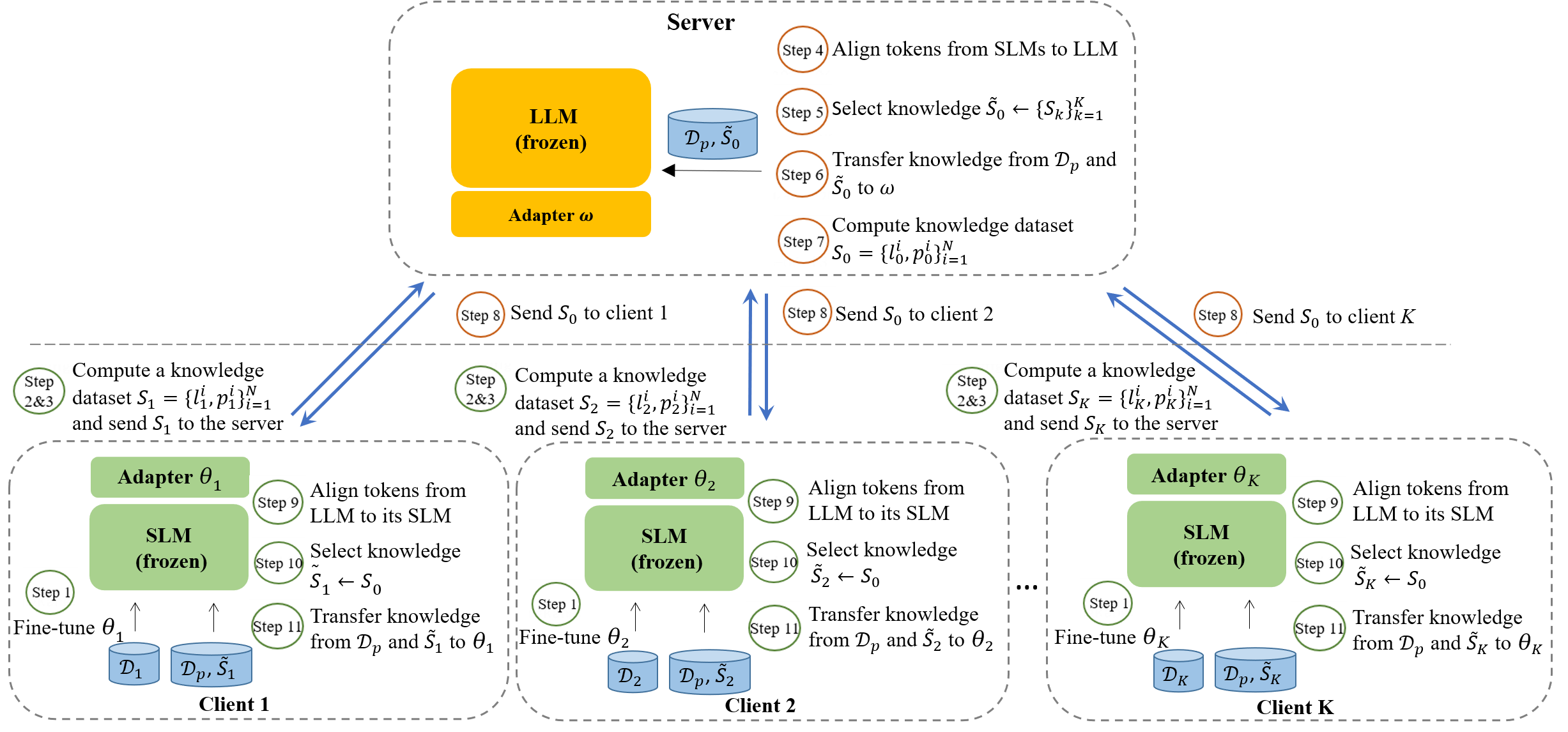
- 两个关键模块:双向 Token 对齐与选择性互知识转移。
- 使用基于最小编辑距离(MinED)的 token 映射,在 LLM 和 SLM 词汇表之间对齐 logits。
- 为服务器端(omega)和客户端(theta)部署 LoRA 适配器,以实现参数高效更新。
- 基于集中式公开数据集的双蒸馏目标(DualMinCE),用于选择用于互相转移的正向知识。
- 交替训练:客户端在私有数据上进行本地微调,然后在公开数据上交换 logits;服务器从客户端 logits 蒸馏并再分发给客户端。
- 目标项 L2 与 L3 将微调损失与蒸馏损失结合,配合平衡参数 lambda。
实验结果
研究问题
- RQ1在联邦设置中,如何实现服务器 LLM 与异质客户端 SLM 之间的有效互知识转移?
- RQ2通过 MinED 的 token 对齐是否能缓解基于 logits 的知识转移中的分词器异质性?
- RQ3相对于基线,在异质、同质和一对一设置下,选择性互知识转移是否能同时提升服务器 LLM 与客户端 SLM 的性能?
主要发现
- 在异质设置下,FedMKT 在八个任务中持续超越对客户端 SLM 的零样本和独立基线。
- 带有 FedMKT 的服务器 LLM 在若干任务上接近集中微调的性能,在某个场景下在 RTE 上达到大约 96% 的集中性能。
- 在同质设置中,FedMKT 相较于零样本获得更优的服务器 LLM 增益,并且对集中/竞争性结果,同时提升 SLM。
- 一对一设置下,FedMKT 超越零样本并接近集中性能于服务器 LLM,同时通过 LLM 指导提升 SLM 的性能。
- 实验覆盖多个模型对(服务器 LLM 加上多样化的客户端 SLMs)和三种设置,展示了该框架的普适性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。