[论文解读] FLAVA: A Foundational Language And Vision Alignment Model
FLAVA 是一个基于单一 Transformer 的模型,在单模态和多模态数据上进行预训练,擅长视觉、语言和多模态推理任务,并在 35 项任务上进行评估。
State-of-the-art vision and vision-and-language models rely on large-scale visio-linguistic pretraining for obtaining good performance on a variety of downstream tasks. Generally, such models are often either cross-modal (contrastive) or multi-modal (with earlier fusion) but not both; and they often only target specific modalities or tasks. A promising direction would be to use a single holistic universal model, as a "foundation", that targets all modalities at once -- a true vision and language foundation model should be good at vision tasks, language tasks, and cross- and multi-modal vision and language tasks. We introduce FLAVA as such a model and demonstrate impressive performance on a wide range of 35 tasks spanning these target modalities.
研究动机与目标
- 说明需要一个同时处理视觉、语言和多模态任务的单一基础模型的动机。
- 提出一个统一的 FLAVA 架构,将单模态与多模态表示融合。
- 开发将对比学习、掩蔽多模态建模和图像-文本匹配相结合的联合预训练目标。
- 展示在使用公开数据的广泛下游任务集合上,FLAVA 的有效性。
- 展示单模态预训练数据如何提升多模态与语言能力。
提出的方法
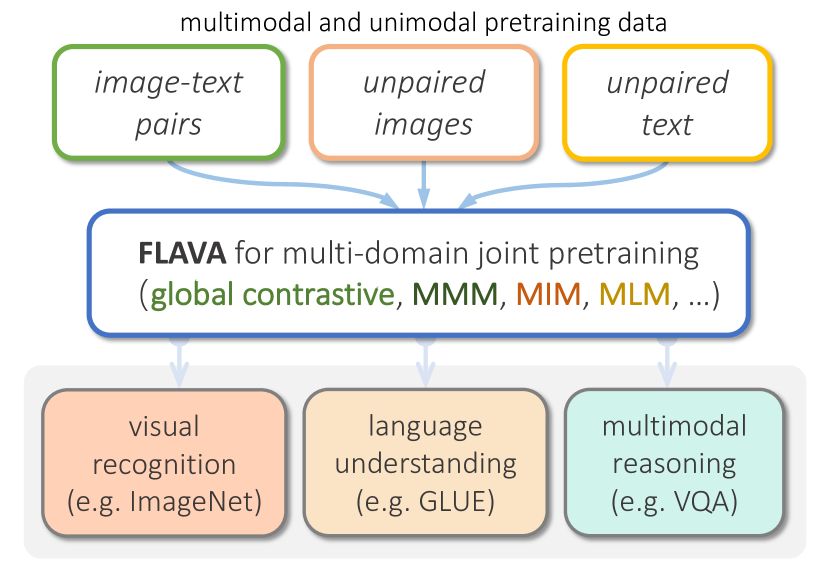
- 架构结合三个 Transformer:用于单模态视觉的图像编码器(ViT),用于单模态语言的文本编码器(基于 ViT),以及用于融合表示的多模态编码器。
- 多模态预训练使用全局对比损失、掩蔽多模态建模(MMM)和图像-文本匹配(ITM)。
- 单模态预训练包括对图像的掩蔽图像建模(MIM)和对文本的掩蔽语言建模(MLM),可选的单模态初始化。
- 联合的单模态和多模态培训交替数据类型(PMD、ImageNet-1K、CCNews、BookCorpus),采用轮流采样。
- 数据源包括 70M 公共可用的图像-文本对(PMD)以及单模态数据集(ImageNet-1K、CCNews、BookCorpus)。
- 该模型使用一个共享主干并为视觉、NLP 和多模态任务应用任务特定的头部。
实验结果
研究问题
- RQ1一个单一的基础模型是否能够从单模态与多模态数据中学习到强大的视觉、语言和多模态推理表示?
- RQ2不同的预训练目标(对比、MMM、ITM、MLM、MIM)如何影响单模态和多模态性能?
- RQ3来自单模态预训练以及跨 GPU 全局反向传播的对比学习有哪些提升?
- RQ4在跨越视觉、NLP 和多模态领域的 35 任务基准上,FLAVA 的表现如何?
- RQ5与在更大规模私有语料上训练的最新多模态模型相比,FLAVA 如何?
主要发现
- FLAVA 在视觉、语言和多模态任务上获得强均值性能,超过了若干消融模型。
- 引入 MMM 和 ITM 目标使多模态结果超过仅对比学习的预训练。
- 具有单模态初始化的联合单模态与多模态预训练可以提升 NLP 性能,在使用预训练的视觉与语言编码器时有显著提升。
- 在公开数据(70M PMD 对 plus 单模态数据)上训练的 FLAVA,仍然与在更大规模私有数据集上训练的模型竞争。
- 对比目标的全局反向传播在多个模态上实现宏平均增益。
- FLAVA 在广泛的任务集合上表现出色,包括 VQA、SNLI-VE、Hateful Memes,以及 GLUE 风格的语言任务。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。