[论文解读] Foundation Models for Biomedical Image Segmentation: A Survey
本综述分析 Segment Anything Model (SAM)及其在发布后前六个月的医学图像分割适应,详述零样本性能、领域特定调优、3D 扩展,以及跨 33 个公开数据集的知识蒸馏。
Recent advancements in biomedical image analysis have been significantly driven by the Segment Anything Model (SAM). This transformative technology, originally developed for general-purpose computer vision, has found rapid application in medical image processing. Within the last year, marked by over 100 publications, SAM has demonstrated its prowess in zero-shot learning adaptations for medical imaging. The fundamental premise of SAM lies in its capability to segment or identify objects in images without prior knowledge of the object type or imaging modality. This approach aligns well with tasks achievable by the human visual system, though its application in non-biological vision contexts remains more theoretically challenging. A notable feature of SAM is its ability to adjust segmentation according to a specified resolution scale or area of interest, akin to semantic priming. This adaptability has spurred a wave of creativity and innovation in applying SAM to medical imaging. Our review focuses on the period from April 1, 2023, to September 30, 2023, a critical first six months post-initial publication. We examine the adaptations and integrations of SAM necessary to address longstanding clinical challenges, particularly in the context of 33 open datasets covered in our analysis. While SAM approaches or achieves state-of-the-art performance in numerous applications, it falls short in certain areas, such as segmentation of the carotid artery, adrenal glands, optic nerve, and mandible bone. Our survey delves into the innovative techniques where SAM's foundational approach excels and explores the core concepts in translating and applying these models effectively in diverse medical imaging scenarios.
研究动机与目标
- 评估在没有领域特定训练的情况下,SAM 如何对医学影像实现泛化。
- 调研将 SAM 适配到医学任务的领域特定调优技术。
- 考察 SAM 的 3D 扩展和多维适应以处理体积数据。
- 探索利用 SAM 输出进行任务特定模型的知识蒸馏策略。
- 识别临床挑战以及 SAM 成功或局限的数据集。
提出的方法
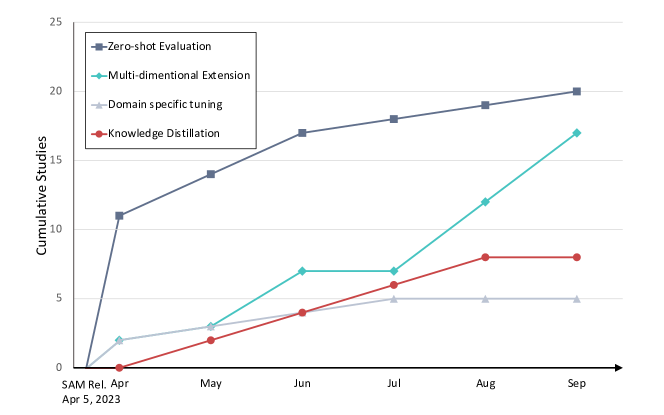
- 回顾并将 SAM 的适应分为四大方法论:零样本评估、适配器/投影/全调优、3D 扩展和知识蒸馏。
- 描述 SAM 的体系结构:图像编码器(MAE/ViT)、提示编码器和轻量级掩码解码器。
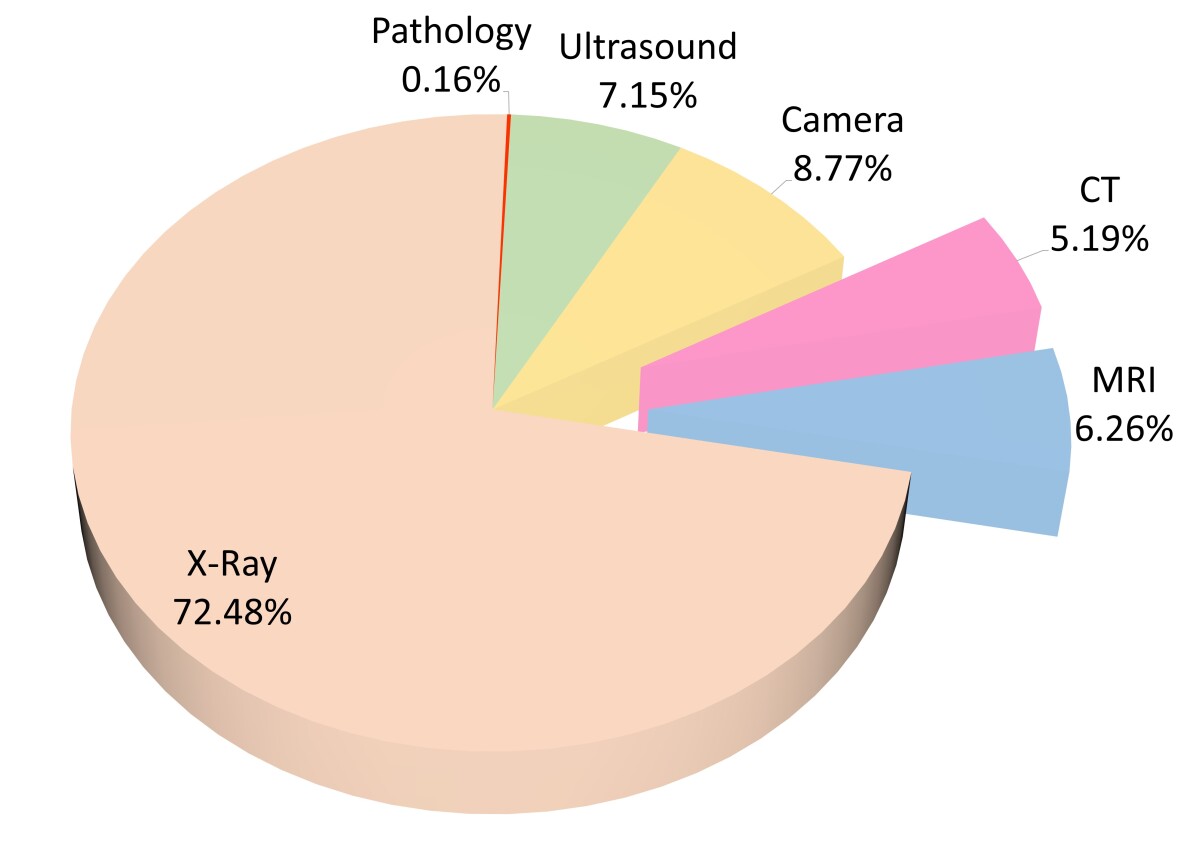
- 整理并分析跨越多模态和多目标的 33 个公开医学影像数据集。
- 讨论 2D 与 3D 的处理方式,包括 2.5D 方法和体积数据的策略。
- 总结早期医学 SAM 研究中观察到的性能趋势和局限性。
实验结果
研究问题
- RQ1在多样数据集上,SAM 的零样本医学图像分割性能如何?
- RQ2哪些领域特定调优策略(投影、适配器、全调优)最能将 SAM 从自然图像桥接到医学影像?
- RQ3在 SAM 的 2D 框架内,如何处理 3D 医学影像数据,以及提出了哪些扩展?
- RQ4知识蒸馏在将 SAM 能力转化为任务特定医学模型中扮演何种角色?
- RQ5基于早期公开数据集,SAM 在哪些主要解剖目标和模态下表现出色或遇到困难?
主要发现
- SAM 在多种医学分割任务中通常达到最先进或具有竞争力的结果,但在颈动脉、肾上腺、视神经和下颌骨等结构上存在空白。
- 领域特定调优(适配器与全调优)和 3D 扩展是提升 SAM 在医疗性能的活跃领域。
- 3D 医学数据通常被处理为 2D切片,或采用 2.5D/体积方法以适应 SAM 的 2D 设计。
- 使用 SAM 输出作为伪标签的知识蒸馏在半监督设置中可提升下游任务模型。
- 存在广泛的数据集景观:33 个公开数据集,跨 7 种模态和 17 种解剖部位,体现了 SAM 的广泛但不均衡的适用性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。